Jekyll2026-05-13T10:45:36+00:00https://pchaigno.github.io/feed.xmlpchaignoPaul Chaignon's blogBPF Selftests: Troubleshooting vmtest.sh2026-05-05T08:26:10+00:002026-05-05T08:26:10+00:00https://pchaigno.github.io/ebpf/2026/05/05/bpf-selftests-troubleshooting-vmtest.shI recently had to reinstall my setup to contribute to Linux on a new laptop, and as usual, ran into a few issues with the BPF selftests.
This short blog post is my attempt to document these issues—and a couple others I had ran into previously—both for my future self and for anyone else interested.
If you run into something not documented here, please give me a shout! I’ll try to keep this up-to-date.
Running the BPF selftests is as simple as:
tools/testing/selftests/bpf/vmtest.sh
or, to run specific tests:
# Run the mcpu=v4 version of the verifier_bounds selftests.
tools/testing/selftests/bpf/vmtest.sh -- ./test_progs-cpuv4 -t verifier_bounds
Unfortunately, because the selftests have a number of dependencies (LLVM, pahole, libelf, etc.) and things sometimes break, it is not that uncommon to run into compilation, linking, and runtime errors.
Conflicting kfunc declarations
In file included from progs/stream.c:8:
bpf_arena_common.h:47:15: error: conflicting types for 'bpf_arena_alloc_pages'
47 | void __arena* bpf_arena_alloc_pages(void *map, void __arena *addr, __u32 page_cnt,
| ^
tools/include/vmlinux.h:152158:14: note: previous declaration is here
152158 | extern void *bpf_arena_alloc_pages(void *p__map, void *addr__ign, u32 page_cnt, int node_id, u64 flags) __weak __ksym;
| ^
In my case, LLVM was too old and generated different prototypes to what the test already had.
The same sort of errors can also happen with older pahole versions.
Solution: Upgrade LLVM and pahole to the latest stable versions.
Undeclared kfuncs
progs/bpf_iter_tasks.c:98:8: error: call to undeclared function 'bpf_copy_from_user_task_str'; ISO C99 and later do not support implicit function declarations [-Wimplicit-function-declaration]
98 | ret = bpf_copy_from_user_task_str((char *)task_str1, sizeof(task_str1), ptr, task, 0);
| ^
1 error generated.
Pahole v1.27 or newer is needed to parse vmlinux and discover exported kfuncs.
With older versions, you’ll run into the above error because the kfuncs declarations are missing.
Workaround: If the error is specific to libpcap, you can also uninstall libpcap-dev as that library is optional and only required to run some selftests.
Incompatible glibc version
./test_progs -t verifier_xdp
./test_progs: /usr/lib/libc.so.6: version `GLIBC_2.38' not found (required by ./test_progs)
That will happen if your host system has a newer glibc version than the selftests VM.
Solution: Use static linking as above.
Cannot find libsystemd
/usr/bin/ld: cannot find -lsystemd: No such file or directory
Since Linux v6.12, the selftests may optionally rely on libpcap-dev.
When linking statically, that can cause the above error because libpcap-dev pulls in a lot of dependencies, including libsystemd.
On some distros1, installing libsystemd doesn’t fix it because its packaging is broken2, causing the following errors:
/usr/bin/ld: (.text.change_capability+0x71): undefined reference to `cap_set_flag'
/usr/bin/ld: (.text.change_capability+0x80): undefined reference to `cap_set_proc'
/usr/bin/ld: (.text.change_capability+0x9f): undefined reference to `cap_free'
Solution: Install libsystemd-dev. Workaround: Uninstall libpcap-dev if libsystemd-dev is broken on your distro.
No rule to make target
make: *** No rule to make target 'bpf_arena_common.h', needed by 'tools/testing/selftests/bpf/arena_htab.test.o'. Stop.
make: *** Waiting for unfinished jobs....
or
make[5]: *** No rule to make target 'str_error.h', needed by 'tools/bpf/resolve_btfids/libbpf/staticobjs/libbpf.o'. Stop.
make[4]: *** [Makefile:152: tools/bpf/resolve_btfids/libbpf/staticobjs/libbpf-in.o] Error 2
make[3]: *** [Makefile:62: tools/bpf/resolve_btfids//libbpf/libbpf.a] Error 2
These errors can happen after changing branches.
They happen because stale .cmd files remain, referencing header files that no longer exist.
For instance, in my second example, I tried to run the selftests on bpf-next after running them on v6.6.
It fails because tools/bpf/resolve_btfids/libbpf/staticobjs/.libbpf.o.cmd from my v6.6 run refers to str_error.h, but that header file was removed in v6.18.
Solution: Run make -C tools/testing/selftests/bpf clean && make -C tools/bpf/resolve_btfids clean to clean up stale object files.
Undefined references to zstd
/usr/bin/ld: /usr/lib/gcc/x86_64-linux-gnu/13/../../../x86_64-linux-gnu/libelf.a(elf_compress.o): in function `__libelf_compress':
(.text+0x113): undefined reference to `ZSTD_createCCtx'
/usr/bin/ld: (.text+0x2a9): undefined reference to `ZSTD_compressStream2'
/usr/bin/ld: (.text+0x2b4): undefined reference to `ZSTD_isError'
/usr/bin/ld: (.text+0x2db): undefined reference to `ZSTD_freeCCtx'
If linking statically, you might hit this on kernels before v6.8 because newer versions of libelf require libzstd, but the kernel doesn’t include it in LD flags.
Solution:8998a479fd96 (v6.8+). Workaround: If the above commit doesn’t apply cleanly, you can also just add -lzstd to LDLIBS manually.
LLVM not detected
Auto-detecting system features:
... llvm: [ OFF ]
There’s a number of reasons this can happen3, but one I encountered recently is when the version of llvm-config doesn’t match the libllvm version you installed.
Solution: Update llvm-config to match the libllvm & clang versions.
Unexpected __counted_by attribute
In file included from test_tag.c:18:
/usr/include/linux/if_alg.h:45:22: error: expected ‘:’, ‘,’, ‘;’, ‘}’ or ‘__attribute__’ before ‘__counted_by’
45 | __u8 iv[] __counted_by(ivlen);
With commit dacbfc167808 (v7.0), two selftests started indirectly relying on the __counted_by macro that wasn’t defined in the tools headers.
That is only an issue if the installed UAPI headers (ex., /usr/include/linux/if_alg.h above) include commit dacbfc167808.
It’s also unlikely to affect many people because the issue was fixed shortly after.
Solution:0c7ae130698e (bpf tree). Workaround: Define __counted_by manually in tools/include/uapi/linux/stddef.h or install an older version of the UAPI headers via make headers_install INSTALL_HDR_PATH=/usr.
State pruning is what helps the BPF verifier in Linux scale to larger programs.
It mitigates the path explosion problem by pruning paths that are equivalent to already-verified paths.
State pruning evolved alongside the verifier for the past decade.
As we illustrated in our talk, it started as a simple optimization and grew into a more complex and efficient component of the verifier.
This timeline tracks the main changes state pruning went through.
Each commit is prefixed with a symbol to indicate the overall impact the change had on the complexity (the “cost” of verification).
For example, ↓ means the commit decreased complexity and therefore helped the verifier scale.
Commits suffixed with a * have been backported to at least one LTS kernel.
As we publish more articles with Mahé, I’ll include more link to Read more on important changes.
757488 Allocate an ID for scalars to propagate infered ranges to identical scalars.
5689d4 Track 64-bit bounded scalar registers as they are spilled to the stack.
v5.15, 2021
bfc6bb Add a pruning point on calls to asynchronous callback functions. Read more
v5.16, 2021
354e8f* Track all bounded scalar registers as they are spilled to the stack.
v6.2, 2022
a3b666* Fix precision propagation in case of ALU operations.
be2ef8* Do not completely disable precise tracking whenever subprogs are used.
f63181* Improve accuracy of precision propagation.
bffdea* Decouple jump history from pruning points.
7a830b* Improve accuracy of precision propagation by actively forgetting precise marks.
v6.3, 2022–2023
4633a0 Fix register comparison in state pruning to take into account ID remapping between paths.
6715df* Relax slack slot equivalence when running with CAP_PERFMON.
v6.4, 2023
4b5ce5 Introduce force pruning points for iter_next kfuncs.
13fbce Improve BPF_JEQ and BPF_JNE dead-branch detection.
v6.5, 2023
407958 Introduce struct backtrack_state to track the precise marking through backtracking.
fde2a3 Support precise tracking for subprogs, including callback functions.
904e6d Share precise mark between all scalars with the same ID.
v6.7, 2023
2793a8* For iter_next loops, require exact state match in state pruning and introduce widening of registers.
42d31d Improve BPF_JEQ and BPF_JNE dead-branch detection by using signed ranges.
ab5cfa* Add a pruning point on calls to synchronous callback functions, fix callback function verification to verify all iterations. Read more
cafe2c* Extend use of register widening to synchronous callback functions.
v6.8, 2023
0acd03* Require precise tracking of R0 on callback function return.
eabe51 Require precise tracking of R0 when checking return code is within expected range.
41f6f6 Precise tracking on spill to the stack even if using non-R10 register.
18a433 Don't trigger precise tracking whenever writing zero register to aligned stack slots.
v6.9, 2024
9a4c57 Don't trigger precise tracking whenever writing zero immediate to aligned stack slots, a pattern common for mcpu=v4.
6efbde Improve state pruning when comparing unbounded spilled register to misc. stack slots.
v6.12, 2024
4bf79f Improving precise tracking at conditional jumps in case of linked registers.
v6.15, 2025
14c855 Data-flow analysis for register liveness, before the actual program analysis.
v6.17, 2025
96c6aa Compute Strongly Connected Components (SCCs) of control-flow graph.
c9e319 Use SCC to improve read and precise marks propagation in case of loops.
v6.18, 2025
b3698c Introduce path-insensitive data flow analysis for liveness tracking.
f41345* Use tnum information to improve BPF_JEQ and BPF_JNE dead-branch detection.
]]>Test Verifier Changes on Cilium’s BPF Programs2025-09-23T08:26:10+00:002025-09-23T08:26:10+00:00https://pchaigno.github.io/ebpf/2025/09/23/test-verifier-changes-on-cilium-bpf-programsAt SIGCOMM’25, I was asked on two occasions how to test verifier changes on Cilium’s BPF programs.
That has been a recurring ask for a while and it makes a lot of sense to want to do this.
Cilium probably still has the largest open sourced BPF programs out there.
There are many heuristics in the Linux verifier, most notably around state pruning.
Thus, changes to the verifier can have hard to predict impacts, on the ability to verify programs or on the complexity, i.e., the number of instructions the verifier has to walk to analyze a program.
Testing your changes on Cilium is one way to evaluate them.
Testing verifier changes on Cilium is also a well-established practice of the kernel community1.
Yet, it can be difficult to know how to test on Cilium.
Its BPF programs can be compiled with many different configurations and only a few really maximize the size and complexity.
In this post, I’ll show how to run Cilium’s complexity test suite on your patched kernel.
The complexity test suite is built to try and maximize the complexity, in an effort to spot complexity issues before they reach users.
We’ll start by building a test VM with your changes, but you can also skip to Run the Complexity Tests if you prefer to boot on your patched kernel directly.
The VM is mostly useful if you don’t want to boot on your kernel or if you want to run the full Cilium end-to-end tests.
If you want to compare complexity numbers between different kernel versions, you may want to build multiple kernels at once.
For example, if your patch is based on bpf-next, you may want to pass run:
KERNEL_VERSIONS="bpf-next my-kernel" make complexity-test
Boot and Prepare the VM
We can then run the VM image using LVH:
cd$WORKDIR/little-vm-helper/
make
./lvh run --host-mount ~/cilium --image /tmp/complexity-test_my-kernel.qcow2
Username is root. There’s no password.
Finally, we need to extract the LLVM version used by Cilium to compile its BPF programs:
If you’re running in the LVH VM, the following command will execute Cilium’s complexity test suite:
cd /host/
export PRIVILEGED_TESTS=true
go test-v-timeout=20m ./pkg/datapath/loader -run"TestPrivilegedVerifier"\--cilium-base-path /host --result-dir /host/datapath-verifier \--kernel-version netnext
/host points to the base of the Cilium clone.
If running this on the host (if you booted on your patched kernel), you’ll need to modify /host in the command to point to the Cilium clone.
The argument --kernel-version points to the set of configurations used by Cilium and, unless testing an old kernel (<= v6.1), it should remain set to netnext.
Parse the Results
Results are found in the datapath-verifier/ directory in the Cilium clone and take the form of a JSON file.
collection refers to a set of BPF programs (typically one of Cilium’s bpf/bpf_[collection].c files). program is the name of the BPF program being tested. build and load are the IDs of the build-time and load-time configurations used for this test case. The combination of program, build, and load can serve as an index for the complexity results.
insns_processed is the number of instructions the verifier had to walk to verify the program. It’s typically referred to as the complexity of the program for that kernel. insns_limit is the complexity limit for that kernel (1M on recent kernels). verification_time_microseconds is the total verification time in microseconds.
max_states_per_insn is the maximum number of verifier states the verifier attached to an instruction in the program. A max_states_per_insn of 5 means that there is at least one instruction in the program for which the verifier saved 5 different states (for different paths). total_states is the number of verifier states that were allocated during verification. Given states can also be freed during the analysis, peak_states gives the maximum number of verifier states that existed at any point in time; it is closely related to the verifier’s memory consumption.
mark_read is the size of the longest parentage chain the verifier had to walk for liveness tracking. stack_depth is the maximum stack depth used by the BPF program.
Comparing Results Across Versions
The largest BPF programs are typically found in the lxc and host collections.
The following command can be used to compare results between different kernels.
It will emit a large number of plots, with comparisons for each program and each configuration.
The following image shows an example plot, for the patched kernel I’m using, in the case of the bpf_host Cilium program.
Run Cilium’s End-to-End Tests
You can also use LVH images with your patched kernel to run end-to-end tests in Cilium’s CI.
To that end, you will need to build additional images:
KERNEL_VERSIONS="my-kernel" make kind
This command will create a new image quay.io/lvh-images/kind-ci:my-kernel@sha256:xxxxxxx.
You will need to retag and push this image to a Docker repository.
To have Cilium’s CI run your kernel, we just need a few changes.
First, we have to edit the kernel: lines in .github/actions/e2e/configs.yaml and .github/actions/e2e/ipsec_configs.yaml to refer to your kernel (i.e., kernel: "my-kernel").
Then, apply the following diff, with whatever Docker repository you used (docker.io/pchaigno in my case):
Commit, open a draft pull request on Cilium’s repositories, and ping your favorite Cilium committer to trigger the end-to-end tests.
Thanks to Simone Magnani for the verifier_diff.py script, to Mahé Tardy for his help running LVH, and to all my colleagues who contributed to our complexity test suite over time!
Last week, the SIGCOMM conference hosted the third edition of the eBPF workshop in Coimbra.
The SIGCOMM website has links to the papers, but cannot link to the presentation slides, so I’m writing this short blog post just to have everything in one place.
The call for papers for the fourth eBPF workshop has opened: ebpf.github.io/2026/cfp.html.
This year, the workshop will be hosted by the ACM SOSP 2026 conference.
The workshop will take place on the 29th of September in Prague.
eBPF’25: Third Edition
uXDP: Frictionless XDP Deployments in Userspace
Yusheng Zheng (UC Santa Cruz), Panayiotis Gavriil (The D. E. Shaw Group), Marios Kogias (Imperial College London) Paper Slides Abstract
Modern network function (NF) deployments face a fundamental trade-off: kernel-based extended Berkeley Packet Filter (eBPF) NFs provide safety, portability, and an extensive tooling ecosystem, but are limited in performance, while kernel-bypass frameworks deliver high throughput but lack integrated verification and ease of deployment. We present uXDP, a new runtime that unifies these worlds by running unmodified, verified XDP programs in userspace. uXDP ensures compatibility and preserves the verification-driven safety, portability, and familiar workflows of eBPF while moving execution into the userspace, enabling more aggressive optimizations and flexibility. Without recompiling eBPF code, uXDP achieves throughput gains of up to 3.3× over in-kernel execution and improves Meta's Katran load balancer performance by 40%, all while retaining the trusted eBPF development model and deployment simplicity.
No Two Snowflakes Are Alike: Studying eBPF Libraries' Performance, Fidelity and Resource Usage
Carlos Machado, Bruno Gião (INESC TEC & U. Minho), Sebastião Amaro, Miguel Matos (IST Lisbon & INESC-ID), João Paulo, Tânia Esteves (INESC TEC & U. Minho) Paper Slides Abstract
As different eBPF libraries keep emerging, developers are left with the hard task of choosing the right one. Until now, this choice has been based on functional requirements (e.g., programming language support, development workflow), while quantitative metrics have been left out of the equation. In this paper, we argue that efficiency metrics such as performance, resource usage, and data collection fidelity also need to be considered for making an informed decision. We show it through an experimental study comparing five popular libraries: bpftrace, BCC, libbpf, ebpf-go, and Aya. For each, we implement three representative eBPF-based tools and evaluate them under different storage I/O workloads. Our results show that each library has its own strengths and weaknesses, as their specific features lead to distinct trade-offs across the selected efficiency metrics. These results further motivate experimental studies to increase the community's understanding of the eBPF ecosystem.
Performance Implications at the Intersection of AF_XDP and Programmable NICs
Marco Molè, Farbod Shahinfar, Francesco Maria Tranquillo, Davide Zoni (Politecnico di Milano), Aurojit Panda (NYU), Gianni Antichi (Politecnico di Milano) Paper Slides Abstract
AF_XDP is emerging as an easier way to implement zero-copy network bypass applications. This is because it allows mixed-mode deployments, where zero-copy and socket-based applications share the same NIC. However, AF_XDP relies on NIC hardware and driver features, but implementing these features on programmable NICs adds resource overheads and increases development complexity and thus might not be desirable. To address this, we examine the feasibility of using eBPF based kernel extensibility to implement the required features, and report on the tradeoff between an eBPF and a native NIC implementation. Our analysis involved updating the OpenNIC driver to support the loading of eBPF/XDP programs and zero-copy AF_XDP. Our implementation is of independent interest because it makes it easier to develop and evaluate alternate designs for mixed-mode zero-copy deployments, and new NIC accelerated applications. Our implementation is open-sourced.
Toward eBPF-Accelerated Pub-Sub Systems
Beihao Zhou, Samer Al-Kiswany, Mina Tahmasbi Arashloo (University of Waterloo) Paper Slides Abstract
Publish-subscribe (pub-sub) systems are a fundamental building block for real-time distributed applications, where high throughput and low latency are critical. Existing brokers can suffer performance bottlenecks as they operate in user space and rely on the socket API and full kernel stack traversal for every message. We present BPF-Broker, a novel pub-sub broker that leverages eBPF to accelerate message dissemination by decoupling the broker's control and data paths. Subscriber management is handled in user space, while message forwarding is done early in the kernel using the TC ingress and XDP hooks. Our evaluation shows that BPF-Broker achieves up to 3× higher throughput compared to our Socket-based baseline broker under high subscriber counts, and up to 2-10× lower end-to-end latency. These results highlight the potential of eBPF in accelerating pub-sub systems.
eBPF enables high-performance kernel-level execution by eliminating networking stack traversal and context switching. Despite the advantages, eBPF applications face strict memory management constraints due to the eBPF verifier requirements that mandate static memory allocation. This limitation imposes a fundamental tradeoff between application performance and memory efficiency, ultimately restricting the potential of eBPF. We present Kerby, a dynamic memory pool allocator for eBPF that enables eBPF applications to dynamically manage pre-allocated memory by representing variable-length data as collections of fixed-size blocks. This allows applications to increase the amount of kernel-resident data while minimizing internal fragmentation. Our preliminary evaluation with key-value store implementations demonstrates that Kerby achieves significant improvements in both memory utilization and throughput.
The Linux BPF framework enables the execution of verified custom bytecode in the critical path of various Linux kernel routines, allowing for efficient in-kernel extensions. The safety properties and low execution overhead of BPF programs have led to advancements in kernel extension use-cases that can be broadly categorized into tracing, custom kernel policies, and application acceleration. However, BPF is fundamentally event-driven and lacks native support for periodic or continuous tasks such as background tracing, metric aggregation, or kernel housekeeping. Existing approaches such as kernel modules with kthreads, userspace daemons, or BPF timers fail to satisfy all the essential requirements for periodic kernel extensions such as fine-grained CPU control, kernel safety, and minimal overhead. To address this gap, we propose SchedBPF—a conceptual framework that enables periodic execution of BPF programs on kernel threads. SchedBPF program executions are sandboxed and preemptible, as governed by the existing BPF verifier and JIT engine. They also adopt time-slice semantics, cgroup-style CPU quotas, and nice-level priority control, similar to kernel threads. SchedBPF aims to enable low-overhead, periodic execution of safe BPF code with fine-grained CPU resource management.
ChainIO: Bridging Disk and Network Domains with eBPF
Zheng Cao, He Xuhang (UC Merced), Yanpeng Hu (ShanghaiTech University), Yusheng Zheng, Yiwei Yang (UC Santa Cruz), Jianchang Su, Wei Zhang (University of Connecticut), Andi Quinn (UC Santa Cruz) Paper Slides Abstract
Modern data-driven services from analytical databases and key-value stores to stream processors suffer high tail-latencies because each disk read and subsequent packet send/recv incurs a separate user-kernel crossing and redundant buffer copy. While Linux's io_uring now supports both block and socket I/O with asynchronous, batched submissions, it does not provide zero-copy transfers between storage and network domains; AF_XDP delivers high-performance packet I/O but is siloed to the network stack. No existing framework transparently unifies these mechanisms end-to-end. We present ChainIO, an eBPF-based system that intercepts and rewrites I/O syscalls, uses ring buffers to pass data descriptors directly between io_uring and AF_XDP, and orchestrates in-kernel execution to chain disk reads into network sends (and vice versa) with full POSIX semantics, fallback safety for unsupported cases, and zero application changes. Our prototype works with unmodified binaries and improves ClickHouse's TPC-H query throughput by up to 39%. ChainIO thus offers a general, safe, and high-performance path for cross-domain I/O optimization in diverse data-intensive workloads.
bpfCP: Efficient and Extensible Process Checkpointing via eBPF
Juntong Deng (King's College London), Stephen Kell (King's College London) Paper Slides Abstract
Live migration, snapshotting, and accelerated startup of applications or containers have long been implemented using checkpoint and restore primitives. To save or 'checkpoint', it is necessary to dump not only its userspace state, but also a large amount of state in the kernel. The current widely used implementation on Linux relies heavily on the /proc file system and special system call interfaces, but these suffer from poor performance and lack extensibility. In this paper, we propose bpfCP, a process checkpointing scheme that dumps in-kernel state via eBPF programs, which improves performance and extensibility. Our preliminary evaluation shows that bpfCP can achieve significant performance improvements in dumping multiple types of in-kernel state of processes.
Automatic Synthesis of Abstract Operators for eBPF
This paper proposes an approach to automatically synthesize sound and precise abstract operators for the static analyzer in the eBPF verifier. The eBPF verifier ensures that only safe user-defined programs are loaded into the kernel. An unsound operator can lead to unsafe programs being accepted, while an imprecise operator can cause safe programs to be rejected. Our approach starts by generating candidate operators using input-output examples tailored for the eBPF verifier's abstract operators and iteratively refines it for soundness and precision. Using this approach, we have generated more precise variants of existing operators. Our approach also generates numerous sound and unsound operators that can serve as test suites for existing eBPF verification and fuzzing frameworks.
Pairwise BPF Programs Should Be Optimized Together
BPF programs are extensively used for tracing and observability in production systems where performance overheads matter. Many individual BPF programs do not incur serious performance degrading overhead on their own, but increasingly more than a single BPF program is used to understand production system performance. BPF deployments have begun to look more like distributed applications; however, this is a mismatch with the underlying Linux kernel, potentially leading to high overhead cost. In particular, we identify that many BPF programs follow a pattern based on pairwise program deployment where entry and exit probes will be attached to measure a single quantity. We find that the pairwise BPF program pattern results in unnecessary overheads. We identify three optimizations—BPF program inlining, context aware optimization, and intermediate state internalization—that apply to pairwise BPF programs. We show that applying these optimizations to an example pairwise BPF program can reduce overhead on random read throughput from 28.13% to 8.98% and on random write throughput from 26.97% to 8.60%. We then examine some key design questions that arise when seeking to integrate optimizations with the existing BPF system.
Kernel Extension DSLs Should Be Verifier-Safe!
Franco Solleza, Justus Adam, Akshay Narayan, Malte Schwarzkopf (Brown University), Andrew Crotty (Northwestern University), Nesime Tatbul (Intel Labs and MIT) Paper Slides Abstract
eBPF allows developers to write safe operating system extensions, but writing these extensions remains challenging because it requires detailed knowledge of both the extension's domain and eBPF's programming interface. Most importantly, the extension must pass the eBPF verifier. This paper argues that DSLs for extensions should guarantee verifier-safety: valid DSL programs should result in eBPF code that always passes the verifier. This avoids complex debugging and the need for extension developers to be eBPF experts. We show that three existing DSLs for different domains are compatible with verifier-safety. Beyond verifier-safety, practical extension DSLs must also achieve good performance. Inspired by database query optimization, we sketch an approach to creating DSL-specific optimizers capable of maintaining verifier-safety. A preliminary evaluation shows that optimizing verifier-safe extension performance is feasible.
Offloading the Tedious Task of Writing eBPF Programs
Xiangyu Gao, Xiangfeng Zhu (University of Washington), Bhavana Vannarth Shobhana (Rutgers University), Yiwei Yang (UC Santa Cruz), Arvind Krishnamurthy, Ratul Mahajan (University of Washington) Paper Slides Abstract
eBPF offers a lightweight method to extend the Linux kernel without modifying the source code in existing modules. However, writing correct and efficient eBPF programs is hard due to its unique verifier constraints and cumbersome debugging processes specific to the kernel execution environment. To tackle such an obstacle, we present a system, SimpleBPF, aiming at offloading the tedious eBPF development task. Developers only need to express their intent in a high-level domain-specific language, while the underlying eBPF code generation is handled automatically. SimpleBPF integrates four key components: a concise DSL, an LLM-based generator, a semantic checker, and an LLM-based optimizer. We use few-shot prompting to build both the code generator and optimizer in SimpleBPF, and evaluate the system on programs written in a representative DSL. The preliminary evaluation result shows that SimpleBPF can generate valid eBPF programs that pass the kernel verifier and exhibit competitive runtime performance. We also outline future directions based on current findings.
Empowering machine-learning assisted kernel decisions with eBPF^ML
Machine-learning (ML) techniques can optimize core operating system paths—scheduling, I/O, power, and memory—yet practical deployments remain rare. Existing prototypes either (i) bake simple heuristics directly into the kernel or (ii) off-load inference to user space to exploit discrete accelerators, both of which incur unacceptable engineering or latency cost. We argue that eBPF, the Linux kernel's safe, hot-swappable byte-code runtime, is the missing substrate for moderately complex in-kernel ML. We present eBPFML, a design that (1) extends the eBPF instruction set with matrix-multiply helpers, (2) leverages upcoming CPU matrix engines such as Intel Advanced Matrix Extensions (AMX) through the eBPF JIT, and (3) retains verifier guarantees and CO-RE portability.
eInfer: Unlocking Fine-Grained Tracing for Distributed LLM Inference with eBPF
Kexin Chu, Jianchang Su, Yifan Zhang (University of Connecticut), Chenxingyu Zhao (University of Washington), Yiwei Yang, Yusheng Zheng (UC Santa Cruz), Shengkai Lin, Shizhen Zhao (Shanghai Jiao Tong University), Wei Zhang (University of Connecticut) Paper Slides Abstract
Modern large language model (LLM) inference workloads run on complex, heterogeneous distributed systems spanning CPUs, GPUs, multi-GPU setups, and network interconnects. Existing profiling tools either incur prohibitive overhead, provide limited visibility, or suffer from vendor lock-in, making real-time, fine-grained performance analysis impractical in production environments. We present eInfer, the first eBPF-based system enabling transparent, low-overhead end-to-end tracing of per-request performance across distributed LLM inference pipelines without requiring application modifications. eInfer uniquely correlates events across CPUs, accelerators, processes, and nodes, delivering unified, vendor-agnostic observability that approaches the accuracy of specialized GPU profiling tools. To address the challenges of scalability dynamic workloads, and instrumentation gaps on accelerators, we design a runtime-adaptive tracing mechanism that maintains comprehensive visibility in real time. Our initial evaluation demonstrates that eInfer delivers precise, low-overhead profiling, enabling critical insights to optimize LLM serving performance in production environments.
InXpect: Lightweight XDP Profiling
Vladimiro Paschali, Andrea Monterubbiano, Francesco Fazzari (University of Rome "La Sapienza"), Michael Swift (University of Wisconsin—Madison), Salvatore Pontarelli (University of Rome "La Sapienza") Paper Slides Abstract
The eBPF eXpress Data Path (XDP) allows high-speed packet processing applications. Achieving high throughput requires careful design and profiling of XDP applications. However, existing profiling tools lack eBPF support. We introduce InXpect, a lightweight monitoring framework that profiles eBPF programs with fine granularity and minimal overhead, making it suitable for XDP-based in-production systems. We demonstrate how InXpect outperforms existing tools in profiling overhead and capabilities. InXpect is the first XDP/eBPF profiling system that provides real-time statistics streaming, enabling immediate detection of changes in program behavior.
BPFflow - Preventing information leaks from eBPF
Chinecherem Dimobi, Rahul Tiwari, Zhengjie Ji, Dan Williams (Virginia Tech) Paper Slides Abstract
eBPF has seen major industry adoption by enterprises to enhance observability, tracing, and monitoring by hooking at different points in the kernel. However, since the kernel is a critical resource, eBPF can also pose as a threat if misused, potentially leading to privilege escalation, information leaks and more. While effective to some extent, existing mitigation strategies like interface filtering are coarse-grained and often over-restrictive. We propose BPFflow, a flexible framework for the system administrator to define policies that specify sensitive data sources, trusted sinks and permitted flows between them. These policies are enforced by an Information Flow Control (IFC) system within the eBPF verifier to track the propagation of sensitive data to prevent unauthorized leakage to userspace or any other untrusted sinks without any runtime overhead.
eBPF’24: Second Edition
An Empirical Study on Challenges of eBPF Application Development
Mugdha Deokar, Jingyang Men, Lucas Castanheira, Ayush Bhardwaj, Theophilus A. Benson Paper Slides Abstract
eBPF has become a crucial tool for the development of specialized and customized network functions, observability frameworks, and security tools. To support these growing use cases, the eBPF ecosystem (i.e., tool chains, set of language primitives, and kernel interfaces) has evolved at an extremely fast pace. Despite its rapid evolution, as a community, we understand very little about the challenges faced by developers in designing eBPF programs or the issues that hamper operators in managing them. This study aims to shed light on these challenges by analyzing eBPF issues on Stack Overflow along several eBPF-specific dimensions. We make several interesting observations that call attention to under-explored areas of the eBPF ecosystem, as well as highlight interesting research directions.
The Linux community has witnessed the rapid development of eBPF technology that allows users to load custom programs into the Linux kernel to extend its capabilities. A key feature that makes eBPF powerful is eBPF maps, which provide data storage and communication capabilities for eBPF programs. However, despite being widely used in eBPF programs, the performance of eBPF maps has received little attention. To understand the performance characteristics of eBPF maps, we conduct a comprehensive benchmark on them. The benchmark results demonstrate the access overhead of different types of eBPF maps and reveal the impact of various factors on the access overhead. By analyzing the benchmark results, we derive some implications for eBPF users to use eBPF maps more efficiently.
Kgent: Kernel Extensions Large Language Model Agent
The extended Berkeley Packet Filters (eBPF) ecosystem allows for the extension of Linux and Windows kernels, but writing eBPF programs is challenging due to the required knowledge of OS internals and programming limitations enforced by the eBPF verifier. These limitations ensure that only expert kernel developers can extend their kernels, making it difficult for junior sys admins, patch makers, and DevOps personnel to maintain extensions. This paper presents Kgent, an alternative framework that alleviates the difficulty of writing an eBPF program by allowing Kernel Extensions to be written in Natural language. Kgent uses recent advances in large language models (LLMs) to synthesize an eBPF program given a user's English language prompt. To ensure that LLM's output is semantically equivalent to the user's prompt, Kgent employs a combination of LLM-empowered program comprehension, symbolic execution, and a series of feedback loops. Kgent's key novelty is the combination of these techniques. In particular, the system uses symbolic execution in a novel structure that allows it to combine the results of program synthesis and program comprehension and build on the recent success that LLMs have shown for each of these tasks individually.
To evaluate Kgent, we develop a new corpus of natural language prompts for eBPF programs. We show that Kgent produces correct eBPF programs on 80%—which is an improvement of a factor of 2.67 compared to GPT-4 program synthesis baseline. Moreover, we find that Kgent very rarely synthesizes "false positive" eBPF programs—i.e., eBPF programs that Kgent verifies as correct but manual inspection reveals to be semantically incorrect for the input prompt. The code for Kgent is publicly accessible at https://github.com/eunomia-bpf/KEN.
Eliminating eBPF Tracing Overhead on Untraced Processes
Milo Craun, Khizar Hussain, Uddhav Gautam, Zhengjie Ji, Tanuj Rao, Dan Williams Paper Slides Abstract
Current eBPF-based kernel extensions affect entire systems, and are coarse-grained. For some use cases, like tracing, operators are more interested in tracing a subset of processes (e.g., belonging to a container) rather than all processes. While overhead from tracing is expected for targeted processes, we find untraced processes—those that are not the target of tracing—also incur performance overhead. To better understand this overhead, we identify and explore three techniques for per-process filtering for eBPF: post-eBPF, in-eBPF, and pre-eBPF filtering, finding that all three approaches result in excessive overhead on untraced processes. Finally, we propose a system that allows for zero-untraced-overhead per-process eBPF tracing by modifying kernel virtual memory mappings to present per-process kernel views, effectively enabling untraced processes to execute on the kernel as if no eBPF programs are attached.
Software updates typically require system reboots, leading to service downtimes. We aim to solve this problem for network components allowing updates while avoiding service degradation. In this paper, we explore the integration of eBPF into the P4 pipeline for efficient packet processing. This way, we combine the flexibility and dynamic adaptability of eBPF with the efficiency of P4. The integration enhances the power of applications and enables the network operator to provide customizable data paths as a service. Our solution allows updating the data path at runtime and without downtime. We implement the approach for the P4 target T4P4S, discuss different performance models, and share implementation insights. The evaluation focuses on the overhead in terms of throughput and the costs of code updates expressed in the latency of the related packets. We show that eBPF execution is possible with reasonable costs, promising dynamic network functions within P4.
eBPF is being used to implement increasingly critical pieces of system logic. eBPF's verifier raises the cost of adoption of the technology, as making programs pass the verifier can be very effortful. We observe that the guarantees provided by the verifier have only been used for the narrow objective of verifying these programs' safety, despite them also enabling the automatic verification of program functional correctness. We envision a framework allowing developers to easily specify and automatically verify their eBPF programs with very little extra cost compared to simply passing the verifier.
We showcase our implementation of DRACO, built on top of KLEE. DRACO allows developers to fully or partially specify eBPF programs, add verification-time assert statements, and reason about multiple eBPF programs interacting with each other and userspace, all at minimal additional cost to the developers. We use DRACO to either fully or partially verify the correctness of several real-world or experimental XDP programs.
Unsafe Kernel Extension Composition via BPF Program Nesting
BPF programs provide the ability to extend the kernel while ensuring safety. The safety guarantees are provided by the in-kernel verifier. However, the verification guarantees may not hold when multiple BPF programs interact with each other through helper functions. This is because, while verifying a BPF program, the verifier considers each BPF program as an individual unit rather than part of a composite system. One aspect affected by this unsafe composition is the kernel stack. In this paper, we highlight how different possible nesting scenarios can affect the safety of the kernel stack. To address this problem, we propose a helper-rooted callgraph-based approach, which enables the verifier to have a global view of the system. By using the callgraph and maximum stack depth information during verification, the verifier will either accept or reject a program by considering all the possible nesting scenarios, which ensures runtime stack safety.
µBPF: Using eBPF for Microcontroller Compartmentalization
Although eBPF (Extended Berkeley Packet Filter) started as a virtualization technology used in the Linux kernel to allow for executing user code inside the kernel in a safe way, it is a general purpose software fault isolation technology. The specification of eBPF instruction set is, also, suitable for using it as a VM for low-end network-enabled embedded devices to achieve software isolation, compartmentalization and allow for updating deployed firmware over-the-air. Existing solutions for running eBPF programs on microcontrollers use bytecode interpreters which incurs execution time and code size overhead compared to native code execution. Additionally, they don't support data relocations which limits the space of programs that can be executed. We implement μBPF - an eBPF virtual machine and a JIT compiler targeting ARMv7-eM architecture. μBPF is compatible with embedded operating systems capable of supporting SUIT firmware update protocol. We implement a secure program deployment pipeline for RIOT - an operating system commonly used in embedded IoT applications. Our evaluation shows that μBPF JIT achieves close-to-native performance and up to of 50% code size reduction compared to the eBPF binaries.
BOAD: Optimizing Distributed Communication with In-Kernel Broadcast and Aggregation
Efficient communication is crucial for the performance of big data and distributed computing systems. Two key communication patterns in these systems are broadcasting, which involves sending data from one to multiple nodes, and aggregation, which combines data from multiple nodes into a single result. Traditional methods using socket-based communication often suffer from significant latency due to frequent user-kernel crossing and network stack processing, limiting the scalability and efficiency of these systems.
To address this issue, we propose BOAD, a new system designed to enhance distributed communication by leveraging eBPF (extended Berkeley Packet Filter) and kernel hooks such as XDP (eX-press Data Path) and TC (Traffic Control). By offloading broadcasting and aggregation tasks to the kernel space, BOAD minimizes the overhead caused by user-kernel crossings and network stack traversals. This innovative approach streamlines data transmission and aggregation, bypassing conventional network layers and substantially reducing communication latency. Our evaluations demonstrate that BOAD significantly enhances the efficiency and scalability of distributed systems, achieving up to 84.5% reduction in broadcast latency compared to baseline implementations.
hyDNS: Acceleration of DNS Through Kernel Space Resolution
Joshua Bardinelli, Yifan Zhang, Jianchang Su, Linpu Huang, Aidan Parilla, Rachel Jarvi, Sameer G. Kulkarni, Wei Zhang Paper Slides Abstract
The Domain Name System (DNS) is a core component of Internet infrastructure, mapping domain names to IP addresses. The recursive resolver plays a critical role in this process, requiring high performance due to multiple request-response exchanges. However, its performance is hindered by costly message copying, user-kernel space transitions, and kernel stack traversal. Kernel bypass techniques can mitigate these issues but often result in resource waste or deployment challenges.
To overcome these limitations, We present hyDNS, a hybrid recursive resolver that combines eBPF offloading in the kernel with a user-space resolver. The DNS kernel cache allows most requests to be served before reaching the kernel network stack. To manage limited DMA memory, excess requests are passed to user space once a threshold is reached, enabling the system to handle high query loads. hyDNS uses programmable NICs to create a scalable kernel cache, implementing a lockless per-core eBPF hash map. Filters on the NIC direct requests to each core. Preliminary results show significant performance improvements with eBPF offloading, achieving up to 4.4× the throughput and a 65% reduction in latency compared to user space implementations.
Unlocking Path Awareness for Legacy Applications through SCION-IP Translation in eBPF
Path-aware networking (PAN) is a novel network paradigm enabling hosts to control network path selection. PAN has been realized on Internet-scale by the SCION routing protocol. Despite the increasing adoption of SCION by ISPs, only few applications offer native SCION support. The SCION-IP Gateway (SIG) tunnels legacy IP traffic over SCION, but does not allow for interoperability with native applications. To unlock PAN for legacy IP applications while maintaining compatibility with native SCION, we introduce SCION-IP translation. We present a network stack component that uses IPv6 sockets for path aware SCION communication and implement a prototype in eBPF. The translator offers more than five times the throughput of the open-source SIG for UDP and achieves 75% of native single-threaded IP application performance.
Traditionally, page faults have been handled by the kernel, with a fixed set of handling routines for different types of faults. However, some applications may benefit from custom page fault handling routines, allowing them to implement advanced functionality, such as more efficient live virtual machine migration and application checkpointing. To this end, Linux introduced the userfaultfd() syscall, which allows applications to handle their page faults in userspace. While userfaultfd() has proven useful in several applications, we identify some key scalability limitations in its design, which limit both performance and adoption. We propose a system that allows using eBPF programs to handle page faults in-kernel, yielding a simpler and more scalable implementation while also enabling novel use cases, such as accelerating the startup of large position-independent executables like browsers.
eBPF’23: First Edition
TCP's Third Eye: Leveraging eBPF for Telemetry-Powered Congestion Control
Jörn-Thorben Hinz, Vamsi Addanki (TU Berlin), Csaba Györgyi (University of Vienna), Theo Jepsen (Intel), Stefan Schmid (TU Berlin) Paper Slides Abstract
For years, congestion control algorithms have been navigating in the dark, blind to the actual state of the network. They were limited to the course-grained signals that are visible from the OS kernel, which are measured locally (e.g., RTT) or hints of imminent congestion (e.g., packet loss and ECN). As applications and OSs are becoming ever more distributed, it is only natural that the kernel have visibility beyond the host, into the network fabric. Network switches already collect telemetry, but it has been impractical to export it for the end-host to react.
Although some telemetry-based solutions have been proposed, they require changes to the end-host, like custom hardware or new protocols and network stacks. We address the challenges of efficiency and protocol compatibility, showing that it is possible and practical to run telemetry-based congestion control algorithms in the kernel. We designed a framework that uses eBPF to run CCAs that can execute different control laws by selecting different types of telemetry. It can be deployed in brownfield environments, without requiring all switches be telemetry-enabled, or kernel recompilation at the end-hosts. When our eBPF program is deployed on hosts without hardware or OS changes, TCP incast workloads experience less queuing (thus lower latency), faster convergence and better fairness.
On Augmenting TCP/IP Stack via eBPF
Sepehr Abbasi Zadeh (University of Toronto, Huawei Technologies Canada Co. Ltd), Ali Munir, Mahmoud Mohamed Bahnasy, Shiva Ketabi (Huawei Technologies Canada Co. Ltd), Yashar Ganjali (University of Toronto, Huawei Technologies Canada Co. Ltd) Paper Slides Abstract
As the data center networks' bandwidth-delay product is increasing and the applications are moving to nano services (with many small flows), managing flows in the network is becoming more challenging. Current TCP/IP stack faces fundamental limitations to meet these challenges. First, it lacks the ability to accurately estimate the network state under dynamic network settings. Second, the current stack is not flexible enough to be extended easily. In this work, we propose a framework, Augmenter, that augments (i.e., increases the network visibility of) the TCP/IP stack to address these challenges. Leveraging eBPF, Augmenter gathers the state of ongoing flows and uses this information to manage other flows that are currently active or arriving in the future. We present one specific use case of setting the initial congestion window of flows dynamically based on network conditions. Our initial tests, show that Augmenter can improve the application performance by up to 1.4x compared to the fixed initial window-based solutions. Implementing Augmenter in the TCP/IP stack itself is not trivial. Augmenter employs eBPF to implement its desired functionality as it enables introducing such changes relatively easy. We discuss potential challenges and solutions in designing and implementing Augmenter applications.
Schooling NOOBs with eBPF
Joel Sommers (Colgate University), Nolan Rudolph, Ramakrishnan Durairajan (University of Oregon) Paper Slides Abstract
While networks have evolved in profound ways, the tools to measure them from end hosts have not kept pace. State-of-the-art tools are ill-suited for elucidating observed network performance impairments and path dynamics, and are susceptible to operational policies of the network. Consequently, the semantic gap between the application-view of network performance vs. actual conditions has resulted in network oblivious (NOOB) systems and applications.
To address this NOOB problem, we examine the Extended Berkeley Packet Filter (eBPF) as a new way to improve the practice of gathering fine-grained network telemetry from the edge. More specifically, by leveraging the safe and efficient in-kernel programming mechanism of eBPF, we design a high-performance telemetry framework called nooBpf with two tools—namely noobprobe and noobflow—to quantify the actual network performance from end hosts and offer unprecedented insights into the flow-level performance, including in-network queuing and routing-induced delays. We illustrate the potential of these two tools to address the NOOB problem through a variety of experiments. The results of our experiments strongly suggest eBPF as a promising foundation for high-performance telemetry and for addressing the NOOB problem.
Supercharge WebRTC: Accelerate TURN Services with eBPF/XDP
Tamás Lévai (Budapest University of Technology and Economics, L7mp Technologies), Balázs Edvárd Kreith (Riverside.fm), Gábor Rétvári (Budapest University of Technology and Economics, L7mp Technologies) Paper Slides Abstract
Real-time communication (RTC) services, from videoconferencing to cloud gaming and remote rendering, are everywhere. WebRTC, an enabler technology for these applications, traditionally relies on a comprehensive NAT traversal protocol suite, most importantly, TURN, to interconnect clients and media servers behind NATs and firewalls. With the demise of residential public IP addresses, these massive-scale TURN services have become an indispensable component of WebRTC applications. Traditionally implemented as multi-protocol user-space packet relays, TURN servers are notoriously resource hungry. In this paper, we propose an eBPF/XDP offload engine to improve TURN server performance. We design a reusable eBPF/XDP TURN offload architecture, create a prototype on top of pion/turn, a popular WebRTC framework written in Go, and show on a fully functional WebRTC testbed that our offload significantly improves throughput and, more importantly, delay, by 2-3x compared to the state-of-the-art.
HEELS: A Host-Enabled eBPF-Based Load Balancing Scheme
Rui Yang (EPFL), Marios Kogias (Imperial College London & Azure Research) Paper Slides Abstract
Layer 4 (L4) load balancing is crucial in cloud computing and elastic microservices. Existing L4 load balancer designs can be split into two main categories: centralized designs using a hardware or software middlebox, and decentralized designs in which every node can play the role of the load balancer. Centralized designs offer better scheduling policies and easier worker node management, but suffer from I/O and CPU limitations. Decentralized designs scale better, but are harder to manage. We introduce HEELS, a novel load balancing scheme designed for internal cloud workloads and microservices, achieving the best of both worlds. HEELS uses the load balancer only during the connection establishment and allows clients and servers to communicate directly after that. Supporting general L4 load balancers and requiring no kernel changes, HEELS is readily deployable on the public cloud. We implement HEELS as a set of eBPF programs split across the client and server. Our evaluation shows that HEELS introduces minimal overheads, works with off-the-shelf load balancers (e.g., Katran by Meta), and significantly reduces the costs of cloud load balancers.
eXpress Data Path Extensions for High-Capacity 5G User Plane Functions
Christian Scheich, Marius Corici, Hauke Buhr, Thomas Magedanz (Fraunhofer FOKUS Institute) Paper Slides Abstract
In 5th Generation mobile networks, a dedicated User Plane Function (UPF) is responsible for connecting users in the Access Networks with the destination networks. In this work, we extend the UPF with eXpress Data Path enhancements to speed up the forwarding of user plane traffic in the GPRS Tunneling Protocol (GTP-U). Also, we develop a Receive Side Scaling method in XDP based on GTP-U header information to distribute incoming uplink traffic to the available CPUs.
PRAVEGA: Scaling Private 5G RAN via eBPF/XDP
Udhaya Kumar Dayalan, Ziyan Wu, Gaurav Gautam, Feng Tian, Zhi-Li Zhang (University of Minnesota – Twin Cities, USA) Paper Slides Abstract
We exploit eBPF+XDP to scale and accelerate software packet processing in (O-RAN compliant) disaggregated 5G RAN (Radio Access Network). We argue that the Central Unit User Plane (CU-UP) component is likely the bottleneck in the 5G RAN user plane data path and therefore focuses on optimizing its performance. We propose an eBPF/XDP-based framework, PRAVEGA, and discuss additional options for further improvements.
Seeing the Invisible: Auditing eBPF Programs in Hypervisor with HyperBee
Yutian Wang, Dan Li (Tsinghua University), Li Chen (Zhongguancun Laboratory) Paper Slides Abstract
The flexibility of eBPF makes it widely used in performance, security, and monitoring. However, this flexibility is a double-edged sword, allowing attackers to use eBPF for malicious purposes. Security researchers have discovered multiple backdoors built by eBPF. Detecting malicious eBPF programs is challenging since eBPF exploits are almost invisible to inspection in both the user and kernel space. To defend against malicious eBPF programs, auditing an operating system's eBPF programs externally at load time is a more efficient approach. We propose HyperBee, a system integrated into the hypervisor that enables auditing of eBPF programs loaded in guests without performance impact during the execution. Guests relinquish their ability to load eBPF programs and must complete verification and JIT compilation of their eBPF programs through HyperBee. We implement a prototype of HyperBee on KVM and the HyperBee-aware guest based on Linux and evaluate its performance when loading eBPF programs. Our results show that HyperBee only brings overhead at load time: 9% extra load time when there is no security policy and 17% extra load time when using security policies against known eBPF malicious programs.
Comparing Security in eBPF and WebAssembly
Jules Dejaeghere (University of Namur), Bolaji Gbadamosi, Tobias Pulls (Karlstad University), Florentin Rochet (University of Namur) Paper Slides Abstract
This paper examines the security of eBPF and WebAssembly (Wasm), two technologies that have gained widespread adoption in recent years, despite being designed for very different use cases and environments. While eBPF is a technology primarily used within operating system kernels such as Linux, Wasm is a binary instruction format designed for a stack-based virtual machine with use cases extending beyond the web. Recognizing the growth and expanding ambitions of eBPF, Wasm may provide instructive insights, given its design around securely executing arbitrary untrusted programs in complex and hostile environments such as web browsers and clouds. We analyze the security goals, community evolution, memory models, and execution models of both technologies, and conduct a comparative security assessment, exploring memory safety, control flow integrity, API access, and side-channels. Our results show that eBPF has a history of focusing on performance first and security second, while Wasm puts more emphasis on security at the cost of some runtime overheads. Considering language-based restrictions for eBPF and a security model for API access are fruitful directions for future work.
Enabling BPF Runtime policies for better BPF management
As eBPF increasingly and rapidly gains popularity for observability, performance, troubleshooting, and security in production environments, a problem is emerging around how to manage the multitude of BPF programs installed into the kernel. Operators of distributed systems are already beginning to use BPF-orchestration frameworks with which they can set load and access policies for who can load BPF programs and access their resultant data. However, other than a guarantee of eventual termination, operators currently have little to no visibility into the runtime characteristics of BPF programs and thus cannot set policies that ensure their systems still meet crucial performance targets when instrumented with BPF programs. In this paper, we propose that having a runtime estimate will enable better policies that will govern the allowed latency in critical paths. Our key insight is to leverage the existing architecture within the verifier to statically track the runtime cost of all possible branches. Along with dynamically determined runtime estimates for helper functions and knowledge of loop-based helpers' effects on control flow, we generate an accurate—although broad—range estimate for making runtime policy decisions. We further discuss some of the limitations of this approach, particularly in the case of broad estimate ranges as well as complementary tools for BPF runtime management.
Enabling eBPF on Embedded Systems Through Decoupled Verification
eBPF (Extended Berkeley Packet Filter) is a Linux kernel subsystem that aims to allow developers to write safe and efficient kernel extensions by employing an in-kernel verifier and just-in-time compiler (JIT). We find that verification is prohibitively expensive for resource-constrained embedded systems. To solve this we describe a system that allows for verification to occur outside of the embedded kernel and before BPF program load time. The in-kernel verifier and JIT are coupled so they must be decoupled together. A designated verifier kernel accepts a BPF program, then verifies, compiles, and signs a native precompiled executable. The executable can then be loaded onto an embedded device without needing the verifier and JIT on the embedded device. Decoupling verification and JIT from load-time opens the door to much more than running BPF programs on embedded devices. It allows larger and more expressive BPF programs to be verified, provides a way for new approaches to verification to be used without extensive kernel modification and creates the possibility for BPF program verification as a service.
Network Profiles for Detecting Application-Characteristic Behavior Using Linux eBPF
Lars Wüstrich, Markus Schacherbauer, Markus Budeus, Dominik Freiherr von Künßberg, Sebastian Gallenmüller (Technical University of Munich), Marc-Oliver Pahl (IMT Atlantique), Georg Carle (Technical University of Munich) Paper Slides Abstract
Applications often show unique communication behavior. Knowledge about this behavior is beneficial in various use cases, such as anomaly or dependency detection. In this paper, we present network profiles that characterize typical application behavior. This requires a reliable and accurate association of processes and applications, which is challenging. We, therefore, introduce an eBPF-based matcher for this task that enables the creation of network profiles. In our evaluation we show that eBPF allows us to efficiently collect the relevant data to build application profiles, addressing issues of other data collection approaches. We further evaluate our work by using a network profile to identify emulated botnet activity masqueraded as a benign process.
RingGuard: Guard io_uring with eBPF
Wanning He (Southern University of Science and Technology), Hongyi Lu (Southern University of Science and Technology (SUSTech)/Hong Kong University of Science and Technology (HKUST)), Fengwei Zhang (Southern University of Science and Technology (SUSTech)), Shuai Wang (HKUST) Paper Slides Abstract
io_uring offers a flexible yet efficient asynchronous I/O paradigm for Linux. Despite a significant performance improvement, it also brings many security concerns to the kernel. Not only does io_uring itself contain multiple vulnerabilities, but it can also be used to bypass existing security mechanisms such as seccomp. To address these problems, this paper proposes a security mechanism named RingGuard that safeguards io_uring with eBPF programs. RingGuard is carefully designed to reduce the overhead of I/O request submission and to ensure the security of inserted eBPF programs. Our evaluation shows that RingGuard provides encouraging security benefits with moderate overhead. For instance, the overhead of RingGuard in file I/O scenarios is merely 7.8%.
Unleashing Unprivileged eBPF Potential with Dynamic Sandboxing
Soo Yee Lim (University of British Columbia), Xueyuan Han (Wake Forest University), Thomas Pasquier (University of British Columbia) Paper Slides Abstract
For safety reasons, unprivileged users today have only limited ways to customize the kernel through the extended Berkeley Packet Filter (eBPF). This is unfortunate, especially since the eBPF framework itself has seen an increase in scope over the years. We propose SandBPF, a software-based kernel isolation technique that dynamically sandboxes eBPF programs to allow unprivileged users to safely extend the kernel, unleashing eBPF's full potential. Our early proof-of-concept shows that SandBPF can effectively prevent exploits missed by eBPF's native safety mechanism (i.e., static verification) while incurring 0%-10% overhead on web server benchmarks.
Practical and Flexible Kernel CFI Enforcement using eBPF
Jinghao Jia, Michael V. Le, Salman Ahmed (IBM Research), Dan Williams (Virginia Tech), Hani Jamjoom (IBM Research) Paper Abstract
Enforcing control flow integrity (CFI) in the kernel (kCFI) can prevent control-flow hijack attacks. Unfortunately, current kCFI approaches have high overhead or are inflexible and cannot support complex context-sensitive policies. To overcome these limitations, we propose a kCFI approach that makes use of eBPF (eKCFI) as the enforcement mechanism. The focus of this work is to demonstrate through implementation optimizations how to overcome the enormous performance overhead of this approach, thereby enabling the potential benefits with only modest performance tradeoffs.
]]>eBPF Research Papers2025-01-07T08:22:10+00:002026-05-13T10:31:00+00:00https://pchaigno.github.io/bpf/2025/01/07/research-papers-bpfWhen I started reading on BPF there weren’t many academic papers to describe how it worked, how it didn’t, or how it is used.
There are many blog posts and informal articles out there, but it’s harder to find self-contained papers with references to older, sometimes unsuspected, related works.
They have become more frequent though, so I wanted to draw up a list with one-sentence summaries for anyone looking for related works or otherwise interested.
I expect this list to only grow with time.
If I want to keep things manageable, I need a way to select papers.
Except I’d rather not be the one having to decide which papers are the “best papers”1.
So I opted to follow the selection from CSRankings: I will only list papers from conference selected by CSRankings by default.
CSRankings tends to put the bar fairly high, but I think there is at least consensus on the top conferences they selected.
I’ve sorted papers according to their type of contribution and the field or area they focus on.
For example, papers improving either the JIT compilers or verifier of eBPF will have improving, jit, and verifier
(see those papers).
If you notice any bug in the selectors, missing papers, or other opportunity for improvement, as usual, don’t hesitate to reach out via one of the contacts at the bottom of the page.
Type selector
Areas selector
Selected 82 papers.
Virtualizing eBPF with Late-Binding
OSDI'26 PaperJ. Zhang, X. Song, D. Du, Y. Xia, B. Zang, H. Chen usingmisc
N/A
PeeR: First-Class Scheduling for Latency Critical eBPF Applications
OSDI'26 PaperJ. Carin, B. Holmes, W. Wang, A. Bhardwaj, M. Ghobadi improvingmisc
Makes BPF programs schedulable and preemptable using sched_ext and cooperative preemption at helper calls.
BeeQoS: A Cloud-Native QoS System for Adaptive and Scalable Multi-Priority Bandwidth Guarantees
WWW'26 PaperJ. Liu, S. Wu, H. Ma, C. Li, H. Yu, D. Jia, F. Li, P. Hu usingnetworking
Implements a QoS system with multi-priority bandwidth guarantees using eBPF for traffic shaping and flow sampling.
Xkernel: Rethinking Performance Tunability of Operating System Kernels
OSDI'26 PaperZ. Chen, W. Zhang, Y. Tang, R. Shu, F. Ren, T. Xu, J. Liu usingmisc
Leverages eBPF kprobes to tune arbitrary performance constants in the kernel at runtime.
HybridMesh: A Hardware-software Hybrid Approach for Accelerating Service Mesh Ingress
NSDI'26 PaperM. You, J. Nam, M. Seo, T. Park, S. Shin usingnetworking
Relies on BPF to help improve performance of their service mesh, by redirecting traffic with tc-bpf and sk_msg, and to handle in-packet metadata.
Remote TCP Connection Offload and Applications
NSDI'26 PaperS. Li, S. W. D. Chien, T. Gao, M. Honda usingnetworking
Relies on tc-bpf to implement flow steering while the tc-flower hardware offload is configured.
KRAKENGUARD: Towards Fine-Grained eBPF Isolation
NSDI'26 PaperJ. Patel, L. G. Buhl-Nielsen, A. Ghosn, M. Kogias improvingsecurity
Implements a userspace policy enforcement engine for BPF programs that handles cross-program interactions.
Tux: Efficient Drop-in Networking for Database Systems
VLDB'25 PaperX. Zhou, V. Leis, X. Yu, M. Stonebraker usingnetworkingmisc
Leverages AF_XDP to build a high-performance networking stack for database systems.
BPF-DB: A Kernel-Embedded Transactional Database Management System For eBPF Applications
SIGMOD'25 PaperM. Butrovich, S. Arch, W. S. Lim, W. Zhang, J. M. Patel, A. Pavlo improvingmiscstorage
Introduces an in-kernel database management system (DBMS) in eBPF, with ACID properties.
Approximation Enforced Execution of Untrusted Linux Kernel Extensions
Sec'25 PaperH. Sun, Z. Su improvingverifier
Relies on state approximations from the Linux verifier to enforce runtime checks on BPF programs.
Deprivileging Low-Level GPU Drivers Efficiently with User-Space Processes and CHERI Compartments
CCS'25 PaperP. Metzger, A. T. Markettos, E. T. Napierała, M. Naylor, R. N. M. Watson, T. M. Jones usingsecuritymisc
Implements in-kernel interrupt handlers on a uBPF VM, for userspace GPU drivers.
Rethinking Tamper-Evident Logging: A High-Performance, Co-Designed Auditing System
CCS'25 PaperR. Zhao, M. Shoaib, V. T. Hoang, W. U. Hassan usingsecurity
Designs a tamper-evident auditing system all in eBPF, including the authentication code computation
Intent-aware Fuzzing for Android Hardened Application
CCS'25 PaperS Jeong, M. Choi, H. Cho, S. Choi, H. Kim, Y. Jeon usingsecuritytracingmisc
While fuzzing Android applications, relies on eBPF to trigger scheduled application behaviors and collect coverage.
Aeolia: A Fast and Secure Userspace Interrupt-Based Storage Stack
SOSP'25 PaperC. Li, R. Yi, Z. Zhang, J. Liu, C. Min, J. Zhang, Y. Luo, X. Wang, Z. Wang, D. Zhou usingstoragemisc
Leverages sched_ext to bridge the scheduling semantic gap between userspace and the kernel when using user interrupts.
Prove It to the Kernel: Precise Extension Analysis via Proof-Guided Abstraction Refinement
SOSP'25 PaperH. Sun, Z. Su improvingverifier
Improves the Linux verifier's precision by refining the abstract state in userspace when needed, and producing a formal proof for it.
SoK: Challenges and Paths Toward Memory Safety for eBPF
S&P'25 PaperK. Huang, J. Sampson, M. Payer, G. Tan, Z. Qian, T. Jaeger analysissecurityverifier
Surveys and evaluates existing work on eBPF memory safety.
SwiftSweeper: Defeating Use-After-Free Bugs Using Memory Sweeper Without Stop-the-World
S&P'25 PaperJ. Ahn, K. Lee, C. Park, H. Moon, Y. Kwon usingmiscsecurity
Designs a memory-sweeping allocator to prevent use-after-free bugs, with a BPF-based custom page fault handler to improve performance.
eBPF Misbehavior Detection: Fuzzing with a Specification-Based Oracle
SOSP'25 PaperT. Lyu, K. K. Dwivedi, T. Bourgeat, M. Payer, M. Xu, S. Kashyap improvingverifier
Introduces a specification-based oracle to fuzz the BPF verifier.
FlexGuard: Fast Mutual Exclusion Independent of Subscription
SOSP'25 PaperV. Laforet, S. Kashyap, C. Iorgulescu, J. Lawall, J.-P. Lozi usingmisc
Improves lock handover time by using eBPF to detect critical section preemptions.
cache_ext: Customizing the Page Cache with eBPF
SOSP'25 PaperT. Zussman, I. Zarkadas, J. Carin, A. Cheng, H. Franke, J. Pfefferle, A. Cidon usingmisc
Extends the kernel with new BPF hooks, kfuncs, and per-cgroup struct_ops to be able to customize the page cache policies.
SIGCOMM'25 Paper TalkT. Pan, E. Song, Y. Zuo, S. Zhang, Y. Song, J. Zhao, W. Hou, J. Lu, X. Sun, S. Zhang, Y. Yang, J. Zhang, T. Huang, B. Lyu, X. Li, R. Wen, Z. Zong, S. Zhu usingnetworking
Improves the performance of their L7 load balancer by customizing the kernel's connection dispatch using sk_reuseport BPF programs.
Extending Applications Safely and Efficiently
OSDI'25 Paper TalkY. Zheng, T. Yu, Y. Yang, Y. Hu, X. Lai, D. Williams, A. Quinn usingtracingmisc
Proposes to implement safe userspace extension mechanisms and observability tools using the bpftime userspace eBPF VM for better efficiency.
Rex: Closing the language-verifier gap with safe and usable kernel extensions
ATC'25 Paper TalkJ. Jia, R. Qin, M. Craun, E. Lukiyanov, A. Bansal, M. Phan, M. V. Le, H. Franke, H. Jamjoom, T. Xu, D. Williams improvingverifier
Reduces false positives by replacing the verifier by a language-based safety approach, with the Rust compiler and runtime checks.
Accelerating Nested Virtualization with HyperTurtle
ATC'25 Paper TalkO. B. Zur, J. Krebs, S. A. Bergman, M. Silberstein usingmisc
Improves nested virtualization performance by offloading logic from the guest hypervisor to the host hypervisor using eBPF.
PageFlex: Flexible and Efficient User-space Delegation of Linux Paging Policies with eBPF
ATC'25 Paper TalkA. Yelam, K. Wu, Z. Guo, S. Yang, R. Shashidhara, W. Xu, S. Novakovic, A. C. Snoeren, K. Keeton usingmisc
Extends the kernel, including with new writable tracepoints, to allow users to customize paging policies.
VEP: A Two-stage Verification Toolchain for Full eBPF Programmability
NSDI'25 Paper TalkX. Wu, Y. Feng, T. Huang, X. Lu, S. Lin, L. Xie, S. Zhao, Q. Cao improvingverifier
Implements a proof-carrying code process for the verification of eBPF using annotations on the C source code.
eTran: Extensible Kernel Transport with eBPF
NSDI'25 Paper TalkZ. Chen, Q. Meng, C. Lao, Y. Liu, F. Ren, M. Yu, Y. Zhou usingnetworking
Designs a framework based on AF_XDP and new networking hooks to allow users to implement custom transport protocols on top of Linux.
NSDI'25 Paper TalkQ. Xu, S. Miano, X. Gao, T. Wang, A. Murugadass, S. Zhang, A. Sivaraman, G. Antichi, S. Narayana usingnetworking
Proposes a method to scale the processing of single-flow traffic on multiple cores using XDP.
P4Control: Line-Rate Cross-Host Attack Prevention via In-Network Information Flow Control Enabled by Programmable Switches and eBPF
S&P'24 Paper TalkO. Bajaber, B. Ji, P. Gao usingnetworkingsecurity
Designs a network defense system that tracks lateral movement across hosts and processes using P4 and eBPF hooks.
BUDAlloc: Defeating Use-After-Free Bugs by Decoupling Virtual Address Management from Kernel
Sec'24 Paper TalkJ. Ahn, J. Lee, K. Lee, W. Gwak, M. Hwang, Y. Kwon usingmiscsecurity
Designs a one-time allocator to detect use-after-free bugs, with a BPF-based custom page fault handler to improve performance.
BeeBox: Hardening BPF Against Transient Execution Attacks
Sec'24 Paper TalkD. Jin, A. J. Gaidis, V. P. Kemerlis improvingverifiersecurity
Combines the verifier's static analysis with SFI-like runtime checks and memory copies to mitigate transient execution attacks.
eAudit: A Fast, Scalable and Deployable Audit Data Collection System
S&P'24 Paper TalkR. Sekar, H. Kimm, R. Aich usingsecurity
Implements a faster auditing system using eBPF at tracepoints.
Toss a Fault to BpfChecker: Revealing Implementation Flaws for eBPF runtimes with Differential Fuzzing
CCS'24 PaperC. Peng, M. Jiang, L. Wu, Y. Zhou improvingverifierjit
Designs a fuzzer for userspace eBPF runtimes, including Windows's, using differential fuzzing, verifier logs, and an intermediate representation of the eBPF bytecode.
NetEdit: An Orchestration Platform for eBPF Network Functions at Scale
SIGCOMM'24 Paper TalkT. A. Benson, P. Kannan, P. Gupta, B. Madhavan, K. S. Arora, J. Meng, M. Lau, A. Dhamija, R. Krishnamurthy, S. Sundaresan, N. Spring, Y. Zhang usingnetworking
Describes an orchestration system for eBPF programs designed to tune the network stack of Meta's services.
Merlin: Multi-tier Optimization of eBPF Code for Performance and Compactness
ASPLOS'24 Paper TalkJ. Mao, H. Ding, J. Zhai, S. Ma usingmisc
Proposes new compiler optimization tailored to the eBPF bytecode.
DINT: Fast In-Kernel Distributed Transactions with eBPF
NSDI'24 Paper TalkY. Zhou, X. Xiang, M. Kiley, S. Dharanipragada, M. Yu usingnetworkingoffload
Designs a new distributed transaction system that offloads common operations to tc and XDP.
BlueSWAT: A Lightweight State-Aware Security Framework for Bluetooth Low Energy
CCS'24 PaperX. Che, Y. He, X. Feng, K. Sun, K. Xu, Q. Li usingsecuritymisc
Proposes to use a userspace eBPF VM to facilitate the distribution of security patches to Bluetooth Low Energy (BLE) devices, to mitigate session-based attacks.
SeaK: Rethinking the Design of a Secure Allocator for OS Kernel
Sec'24 Paper TalkZ. Wang, Y. Guang, Y. Chen, Z. Lin, M. Le, D. K Le, D. Williams, X. Xing, Z. Gu, H. Jamjoom usingsecuritymisc
Builds a secure allocator for the kernel, to separate security-sensitive objects, using new BPF helpers.
Rethinking Process Management for Interactive Mobile Systems
MobiCom'24 PaperJ. Zheng, Z. Li, F. Qian, W. Liu, H. Lin, Y. Liu, T. Xu, N. Zhang, J. Wang, C. Zhang usingmisc
Leverages eBPF to measure the usage of hardware resources by Android applications and investigate slow UI responsiveness problems.
MegaTE: Extending WAN Traffic Engineering to Millions of Endpoints in Virtualized Cloud
SIGCOMM'24 Paper TalkC. Miao, Z. Zhong, Y. Xiao, F. Yang, S. Zhang, Y. Jiang, Z. Bai, C. Lu, J. Geng, Z. He, Y. Wang, X. Zou, C. Yang usingnetworking
Relies on eBPF to identify traffic sources and enforce traffic engineering via segment routing across the WAN.
FetchBPF: Customizable Prefetching Policies in Linux with eBPF
ATC'24 Paper TalkX. Cao, S. Patel, S. Y. Lim, X. Han, T. Pasquier usingmisc
Extends the kernel with new BPF hooks and helpers to be able to customize memory prefetching policies.
Validating the eBPF Verifier via State Embedding
OSDI'24 Paper TalkH. Sun, Z. Su improvingverifier
Devises a test oracle to fuzz the eBPF verifier by embedding correctness checks in the BPF program.
Hive: A Hardware-assisted Isolated Execution Environment for eBPF on AArch64
Sec'24 Paper TalkP. Zhang, C. Wu, X. Meng, Y. Zhang, M. Peng, S. Zhang, B. Hu, M. Xie, Y. Lai, Y. Kang, Z. Wang improvingverifiersecurity
Proposes to replace the static analysis of the verifier with a hardware-based runtime isolation for ARM64.
End-to-End Mechanized Proof of a JIT-Accelerated eBPF Virtual Machine for IoT
CAV'24 PaperS. Yuan, F. Besson, J.-P. Talpin improvingjit
Correctness proof for the eBPF JIT compiler used in the micro-controller RIOT kernel.
Fast, Flexible, and Practical Kernel Extensions
SOSP'24 PaperK. K. Dwivedi, R. Iyer, S. Kashyap improvingverifier
Extends the Linux verifier with limited runtime checks and in a backward compatible way, significantly improving eBPF's expressibility.
MOAT: Towards Safe BPF Kernel Extension
Sec'24 Paper TalkH. Lu, S. Wang, Y. Wu, W. He, F. Zhang improvingverifiersecurity
Hardens eBPF in Linux by leveraging Intel MPK and adding runtime checks for helpers.
Cross Container Attacks: The Bewildered eBPF on Clouds
Sec'23 Paper TalkY. He, R. Guo, Y. Xing, X. Che, K. Sun, Z. Liu, K. Xu, Q. Li analysissecurity
Highlights that eBPF tracing programs can be used to escape container boundaries and the impact on cloud and online coding platforms.
λ-IO: A Unified IO Stack for Computational Storage
FAST'23 Paper TalkZ. Yang, Y. Lu, X. Liao, Y. Chen, J. Li, S. He, J. Shu usingstorage
Modifies eBPF to implement a unified IO stack spanning the kernel and storage devices, in the context of in-storage computing.
eHDL: Turning eBPF/XDP Programs into Hardware Designs for the NIC
ASPLOS'23 Paper TalkA. Rivitti, R. Bifulco, A. Tulumello, M. Bonola, S. Pontarelli usingnetworking
Introduces a synthesis tool that generates FPGA pipelines for NICs from unmodified XDP programs.
Fuzz on the Beach: Fuzzing Solana Smart Contracts
CCS'23 PaperS. Smolka, J.-R. Giesen, P. Winkler, O. Draissi, L. Davi, G. Karame, K. Pohl improvingsecuritymisc
Fuzzes Solana smart contracts, including those compiled to eBPF bytecode, by extending Solana's userspace eBPF VM with six bug oracles and coverage feedback.
xBGP: Faster Innovation in Routing Protocols
NSDI'23 Paper TalkT. Wirtgen, T. Rousseaux, Q. De Coninck, N. Rybowski, R. Bush, L. Vanbever, A. Legay, O. Bonaventure usingnetworking
Designs an extension mechanism for BGP using a userspace implementation of eBPF and several C verification tools to replace and extend the Linux verifier.
Taking 5G RAN Analytics and Control to a New Level
MobiCom'23 PaperX. Foukas, B. Radunovic, M. Balkwill, Z. Lai usingnetworking
Proposes to extend virtualized Radio Access Network (vRAN) functions using a userspace BPF implementation and the PREVAIL verifier, with a new runtime check to bound the execution time.
Network-Centric Distributed Tracing with DeepFlow: Troubleshooting Your Microservices in Zero Code
SIGCOMM'23 Paper TalkJ. Shen H. Zhang, Y. Xiang, X. Shi, X. Li, Y. Shen, Z. Zhang, Y. Wu, X. Yin, J. Wang, M. Xu, Y. Li, J. Yin, J. Song, Z. Li, R. Nie usingtracing
Presents a distributed tracing framework for troubleshooting microservices that leverages eBPF for data collection.
Tigger: A Database Proxy That Bounces with User-Bypass
VLDB'23 PaperM. Butrovich, K. Ramanathan, J. Rollinson, W. S. Lim, W. Zhang, J. Sherry, A. Pavlo usingnetworkingoffload
Offloads PostgreSQL connection pooling and mirroring to the kernel using sockmap BPF programs.
Electrode: Accelerating Distributed Protocols with eBPF
NSDI'23 Paper TalkY. Zhou, Z. Wang, S. Dharanipragada, M. Yu usingnetworkingoffload
Offloads common Paxos networking operations to tc and XDP to improve performance.
Verifying the Verifier: eBPF Range Analysis Verification
CAV'23 PaperH. Vishwanathan, M. Shachnai, S. Narayana, S. Nagarakatte improvingverifier
Automatically and formally proves the ranges analysis of the Linux verifier.
EPF: Evil Packet Filter
ATC'23 Paper TalkD. Jin, V. Atlidakis, V. P. Kemerlis analysissecurity
Presents an approach to bypass various kernel isolation techniques by abusing the cBPF infrastructure.
Tastes Great! Less Filling! High Performance and Accurate Training Data Collection for Self-Driving Database Management Systems
SIGMOD'22 PaperM. Butrovich, W. S. Lim, L. Ma, J. Rollinson, W. Zhang, Y. Xia, A. Pavlo usingtracingmisc
Implements a BPF-based data collection framework for database management systems (DBMSes).
Domain Specific Run Time Optimization for Software Data Planes
ASPLOS'22 Paper TalkS. Miano, A. Sanaee, F. Risso, G. Rétvári, G. Antichi usingnetworking
Optimizes datapath binaries, including eBPF bytecodes, based on traffic patterns.
End-to-end Mechanized Proof of an eBPF Virtual Machine for Micro-controllers
CAV'22 PaperS. Yuan, F. Besson, J.-P. Talpin, S. Hym, K. Zandberg, E. Baccelli improvingverifier
Correctness proof for the eBPF interpreter and verifier used in the micro-controller RIOT kernel.
OSDI'22 Paper TalkS. Park, D. Zhou, Y. Qian, I. Calciu, T. Kim, S. Kashyap usingmisc
Allows Linux users to customize kernel lock policies using eBPF and according to the applications' needs and hardware characteristics.
RapidPatch: Firmware Hotpatching for Real-Time Embedded Devices
Sec'22 Paper TalkY. He, Z. Zou, K. Sun, Z. Liu, K. Xu, Q. Wang, C. Shen, Z. Wang, Q. Li usingmisc
Implements a hotpatching mechanism for real-time OSes using eBPF, a modified verifier, and additional runtime checks.
SPRIGHT: Extracting the Server from Serverless Computing! High-Performance eBPF-Based Event-Driven, Shared-Memory Processing
SIGCOMM'22 Paper TalkS. Qi, L. Monis, Z. Zeng, I.-C. Wang, K. K. Ramakrishnan usingnetworking
Leverages various eBPF hooks to improve the performance of Knative, a container-based serverless platform.
Faster Software Packet Processing on FPGA NICs with eBPF Program Warping
ATC'22 Paper TalkM. Bonola, G. Belocchi, A. Tulumello, M. Spaziani Brunella, G. Siracusano, G. Bianchi, R. Bifulco usingnetworking
Improves the performance of hXDP, an eBPF processor for FPGA NICs, via peephole optimization, thereby replacing series of instructions with optimized hardware implementations.
XRP: In-Kernel Storage Functions with eBPF
OSDI'22 Paper TalkY. Zhong, H. Li, Y. J. Wu, I. Zarkadas, J. Tao, E. Mesterhazy, M. Makris, J. Yang, A. Tai, R. Stutsman, A. Cidon usingstorageoffload
Offloads processing to the NVMe drivers using BPF, to reduce kernel overhead in storage applications
Sound, Precise, and Fast Abstract Interpretation with Tristate Numbers
CGO'22 Paper TalkH. Vishwanathan, M. Shachnai, S. Narayana, S. Nagarakatte improvingverifier
Formally proves and improves the Linux verifier operations on tristate numbers for the range analysis.
Synthesizing Safe and Efficient Kernel Extensions for Packet Processing
SIGCOMM'21 Paper TalkQ. Xu, M. D. Wong, T. Wagle, S. Narayana, A. Sivaraman usingnetworking
Proposes a synthesis-based compiler that optimizes eBPF programs while ensuring they still pass the Linux verifier.
BMC: Accelerating Memcached using Safe In-Kernel Caching and Pre-Stack Processing
NSDI'21 Paper Talk SummaryY. Ghigoff, J. Sopena, K. Lazri, A. Blin, G. Muller usingnetworkingoffload
Speeds up Memcached with an XDP-based, transparent, first-level cache.
An Analysis of Speculative Type Confusion Vulnerabilities in the Wild
Sec'21 Paper TalkO. Kirzner, A. Morrison analysissecurity
Describes how eBPF can be leveraged to create speculative type confusion gadgets in the kernel.
Syrup: User-Defined Scheduling Across the Stack
SOSP'21 Paper TalkK. Kaffes, J. Humphries, D. Mazières, C. Kozyrakis usingnetworking
Proposes an eBPF-based framework to enable users to write application-specific scheduling policies for threads, network packets, and network connections.
Revisiting the Open vSwitch Dataplane Ten Years Later
SIGCOMM'21 PaperW. Tu, Y.-H. Wei, G. Antichi, B. Pfaff usingnetworking
Describes how production experience with Open vSwitch over a decade led to the development of its new AF_XDP-based datapath.
Synthesizing JIT Compilers for In-Kernel DSLs
CAV'20 PaperJ. Van Geffen, L. Nelson, I. Dillig, X. Wang, E. Torlak improvingjit
Synthesizes eBPF and cBPF JIT compilers, which are proven to be formally correct, from DSL interpreters.
hXDP: Efficient Software Packet Processing on FPGA NICs
OSDI'20 Paper Talk SummaryM. Spaziani Brunella, G. Belocchi, M. Bonola, S. Pontarelli, G. Siracusano, G. Bianchi, A. Cammarano, A. Palumbo, L. Petrucci, R. Bifulco usingnetworking
Investigates the execution of XDP programs on FPGA NICs by implementing an interpreter.
Specification and Verification in the Field: Applying Formal Methods to BPF Just-in-Time Compilers in the Linux Kernel
OSDI'20 Paper TalkL. Nelson, J. Van Geffen, E. Torlak, X. Wang improvingjit
Applies formal verification techniques to the eBPF JIT compilers and implements a new formally-verified JIT compiler for 32-bit RISC-V.
Scaling Symbolic Evaluation for Automated Verification of Systems Code with Serval
SOSP'19 PaperL. Nelson, J. Bornholt, R. Gu, A. Baumann, E. Torlak, X. Wang improvingverifier
Proposes a framework to developing verifiers for system software, including eBPF, by lifting existing interpreters under symbolic execution.
Extension Framework for File Systems in User Space
ATC'19 Paper TalkA. Bijlani, U. Ramachandran usingstorageoffload
Enables eBPF support in the FUSE interface to improve the performance of user-space file systems by offloading operations to the kernel.
Pluginizing QUIC
SIGCOMM'19 PaperQ. De Coninck, F. Michel, M. Piraux, F. Rochet, T. Given-Wilson, A. Legay, O. Pereira, O. Bonaventure usingnetworking
Designs an extension mechanism for QUIC using a userspace implementation of eBPF with SFI-like runtime checks.
Simple and Precise Static Analysis of Untrusted Linux Kernel Extensions
PLDI'19 Paper Talk SummaryE. Gershuni, N. Amit, A. Gurfinkel, N. Narodytska, J. A. Navas, N. Rinetzky, L. Ryzhyk, M. Sagiv improvingverifier
Introduces PREVAIL, an alternative to the Linux eBPF verifier based on abstract interpretation and now used in Windows.
The Design and Implementation of Hyperupcalls
ATC'18 PaperN. Amit, M. Wei usingmisc
Leverages eBPF to bridge the semantic gap of virtualization, by letting hypervisors execute verified code from the guests.
Jitk: A Trustworthy In-Kernel Interpreter Infrastructure
OSDI'14 Paper TalkX. Wang, D. Lazar, N. Zeldovich, A. Chlipala, Z. Tatlock improvingjit
Proposes a formally-verified infrastructure to compile high-level rules into cBPF bytecode and machine code.
Safe Kernel Extensions Without Run-Time Checking
OSDI'96 PaperG. C. Necula, P. Lee improvingverifier
Proposes kernel extensions in the form of proof-carrying code and compares it to cBPF.
The BSD Packet Filter: A New Architecture for User-level Packet Capture
USENIX Winter'93 PaperS. McCanne, V. Jacobson foundationnetworking
The original cBPF paper, describing a register-based packet filter for BSD.
Thanks to Kahina for her reviews and for reporting multiple bugs with the early version of the selectors.
Of course, I can’t really escape chosing a method to select papers, so it’s not as if this is completely objective either. ↩
]]>First Cilium Pull Request2024-12-05T08:26:10+00:002025-01-07T10:31:00+00:00https://pchaigno.github.io/cilium/2024/12/05/first-cilium-pull-requestCilium has a fairly large codebase, with many different features, implemented in two very different languages1, and covered by an extensive CI.
Contributing for the first time can be a daunting task.
Nevertheless, Cilium has received code contributions from more than 800 people to date!
In every release cycle, many people are contributing for the first time.
I’m hoping this post can serve as a getting started guide for them, with some advice also useful to more experienced contributors.
This is not the official contribution guide, but my own advice. Especially when writing about Cilium, it’s worth restating that opinions expressed in this blog are my own and not the project’s or my employer’s.
When searching for something to contribute, a good place to start is probably the good-first-issues.
It’s best to select one where you have some idea how to make the changes.
Expecting other contributors to tell you which exact places to patch in the codebase is not a good solution.
Small documentation changes also make for excellent first contributions in my opinion because they are typically easier to get merged and still allow you to get familiar with the process.
That being said, a pull request fixing just a typo is probably not worth it.
Fixing something that you noticed was broken or unideal while running Cilium is usually the best, mostly because you’ll be familiar with the issue and more motivated.
Larger Contributions
The process for making larger contributions is typically a bit different, as you’ll need to discuss it with the community first.
Submitting a large set of changes without first discussing with the community is unlikely to lead to any successful outcome.
Cilium Feature Proposals
For larger contributions, especially new features, it’s best to go through the Cilium Feature Proposal (CFP) process first.
The usual steps are to start writing it out in a Google document (see examples), ask for reviews in the community meeting, then submit it to cilium/design-cfps once it’s more stable.
You don’t need to wait for the CFP to be merged before submitting a first implementation as draft pull requests.
Splitting in Pull Requests
Prefer small pull requests.
Preparatory changes can be their own pull request if they make sense on their own.
People sometimes also split the feature changes themselves, between datapath and agent changes, ingress and egress, or whatever else makes sense.
In that case, it’s best to hide the feature from users (ex., via a hidden flag) before all pieces are in.
Preparing the Branch
Within a pull request, commits should be kept small, each with few changes.
Refactoring changes should be separated from functional changes.
Tests can be separate commits as well.
Commit descriptions should explain the why.
You will often also need to explain the what, if it’s not obvious from reading the code.
The commit title should tell the what.
For example, the following commit has a title that explains the what (we ignore a drop reason in the CLI) and a body that explains the why (because it should always be ignored so we might as well ignore it by default).
commit a92f8c3e0ac44f4d7ed7ee210c000da5ea93f9aa
Author: Paul Chaignon <paul.chaignon@gmail.com>
Date: Tue Oct 29 11:12:23 2024 +0100
cilium-cli: Ignore "No egress gateway found" drops
Those drops currently need to be ignored in all tests involving the
egress gateway, so we might as well ignore them by default in the
connectivity tests.
Signed-off-by: Paul Chaignon <paul.chaignon@gmail.com>
When describing what the commit changes, if you find yourself writing a list, it's usually a good indication that your commit is too big: each element of the list should be its own commit instead.
Remember to sign off your commits, with git commit -s.
If you forget, a bot will come complain on your pull request, even if it’s still in draft.
I recommend adding a Git hook to never forget.
If you’re making functional changes, you should definitely test them locally by deploying Cilium.
Opening the Draft Pull Request
Summarize the changes in the pull request description.
It doesn’t have to be long; the main description is in commits.
I typically don’t write more than a sentence per commit and sometimes just a couple sentences to sum up the whole changeset.
If you have a single commit, the pull request description can be that commit’s description2.
If you have rights to set labels, you should set the release-note/{misc,minor,major,bugfix,ci} label with one of its five values.
If not, one of the reviewers will set it.
This label determines where in the release notes your pull request will be announced.
You should only set release-note/bug if you are fixing a bug that was exposed to users (that is, a released bug).
release-note/major is for major changes, such as new features.
release-note/minor is for any other change with user-visible impacts (ex., a new metric).
Finally, release-note/ci is for tests and release-note/misc for everything else.
See the existing release notes for examples.
If you are making a user-visible change3, you should also fill in the release note itself, at the bottom of the pull request description.
This is particularly important for bug fixes.
It will be used in release notes to described how your changes affect users.
You should be specific so that users can understand if they are affected and how.
For example, for a bug fix:
```release-note
Fix transient connectivity issue on upgrades when IPsec and IPv6 are enabled.
```
Always open in draft first!
That way you can run the CI before asking people for reviews.
There’s no point asking for reviews if the CI is surfacing bugs in your changes.
The CI consist of initial tests, triggered whenever you push, and end-to-end tests, which need to be manually triggered.
Wait for all initial tests to be finished.
It takes about 20 minutes.
Once they all completed, ask an Organization Member to trigger the end-to-end tests.
If you don’t know one, ask in #development on the Cilium Slack.
End-to-end tests can take up to several hours to finish, though most finish in less than an hour.
Note that If you only have documentation changes, you probably don’t need to trigger end-to-end tests before making the pull request ready for reviews; the tests will all be skipped anyway.
Optional: If you have rights to assign reviewers, just before making ready for reviews, it may be worth selecting reviewers you know are familiar with your changes, for example people who reviewed the CFP.
Consider that you will need reviews covering each review team listed in Reviewers, so asking for reviews from people not on those teams won’t help you achieve that specific goal4.
Don’t assign specific people without asking them!
Make the pull request ready for reviews.
Wait for reviews.
After a few days without response, post a message in #development on Slack.
If you still don’t get the reviews, you can try to ping the assigned reviewers directly in Slack.
Review rounds
Try to address reviews quickly.
The faster you re-requested a review, the more likely reviewers are to still have all the context.
For that same reason, I wouldn’t recommend making a pull request ready for reviews just before leaving on holiday.
Do not address reviews in separate commits.
You should fix issues in the commit where they were introduced.
Reviewers will typically re-review the whole set of commits anyway.
Of course, if you introduce new changes, independent of previous commits, it can be a new commit.
Whenever pushing a new version, make sure to also rebase so you don’t end up with failing tests or merge conflicts because your base is too old.
You can use the following commands to rebase:
Don’t forget to mark conversations in the pull request as resolved if you addressed them.
The pull request cannot be merged until all conversations have been resolved.
After addressing a review, always re-request a review from the reviewer.
Some reviewers will nitpick.
Most will indicate which requests for changes are nitpicks.
That’s fine and a good indication those requests are optional.
It probably helps to address them though, especially if you’re a new contributor.
Passing the CI
For each failing CI job, first check the error and if it could be related to your changes.
Is it in the same code area?
Are almost all tests failing?
Then, it’s likely related to your changes.
If it doesn’t look related, ask for someone to re-trigger.
Note reviewers may sometimes do this while reviewing, to help you out.
If the same tests fail again with the same errors, it’s either related to your changes or something is broken in main.
To check the second possibility, search for the error in GitHub issues.
If you don’t find any issues, check if those same tests are passing on main.
To find the test runs on main, go to Actions, select the workflow on the left, then filter by event:push or event:schedule5.
If the main runs are consistently failing, ask for help in #development.
Being an Organization Member helps a lot here because you can retrigger tests yourself without having to wait for someone else to do it.
You can do this using the trigger phrases indicated in the name of many CI tests (ex. /ci-e2e-upgrade).
Being a Reviewer is even better because then you can retrigger only failing jobs in the failing workflow (see screenshot below).
See the section below on how to become an org member.
If you suspect your changes are causing the test failure, you might want to run the same tests locally.
That is unfortunately not trivial because Cilium has many different ways it runs its tests in CI.
Instead, I would recommend to first check the artifacts; Cilium sysdumps are attached for each failure6 and they contain a lot of debugging information.
If that isn’t enough, you can find how to reproduce locally by checking the sources for the workflow.
You can see the sources by clicking on “Workflow file” in the bottom left.
Don’t rebase your pull request just because a couple CI jobs are failing.
When you rebase, you start from scratch in terms of CI.
There are almost always a few CI jobs failing so if you rebase each time, you will never reach a green CI.
That being said, if you didn’t rebase your pull request in a while (ex., your base is more than a week old), rebasing may help avoid CI failures.
The CI is in a bad state and has basically always been in Cilium.
Cilium's CI is huge because it needs to cover many different features, environments, and kernels.
It is thus unsurprising that it requires a lot of maintenance.
My only advise is to be patient and ask for help if you can't figure out what's happening.
Merging!
Once all review teams are covered with Approved reviews and CI is green, the pull request should be mergeable.
You may need to ping in #development to ask one of the committers to merge it.
Common Questions
What Should I Do If the needs-rebase Label is Added?
If the needs-rebase label was added, it can be because there are merge conflicts or because a reviewer thinks it would help reduce CI failures.
If there are merge conflicts, git will complain when running git rebase upstream/main.
Follow its instructions, fix the conflicts, and finish the rebase before pushing your updated branch.
What If I Want to Fix Something that is Broken in a Previous Release?
For bugs in stable branches, fixes should be sent to main first. After they are merged, they will be backported to the affected branches if they meet the backport criteria.
If the bug is fixed in main by another pull request, you should check on that other pull request if the backport was considered.
If it wasn’t and you think it matches the backport criteria, you can ask in the merged pull request to consider backporting it.
Don’t forget to explain why you think it should be backported.
For example: you reproduced the issue on that version and it matches backport criteria X and Y.
If the bug doesn’t exist in main but not because it was fixed by a pull request (ex. the feature was later removed or refactored), then you can send a fix directly to the affected branch.
Be sure to clearly explain why you’re sending the fix without going through main.
Note that it still needs to match the backport criteria even if it’s not actually being backported.
How and When to Move up the Contributor Ladder?
Cilium has a contributor ladder with multiple roles you can read about here. You can ask to move up the ladder on that same repository. The TL;DR of roles is as follows:
Community Contributor: Everyone who contributes.
Organization Member:
Main power: Trigger CI tests by youself with /test, /ci-e2e-upgrade, and similar comments.
When: After making several pull requests.
I’d say minimum ~4, but the exact number isn’t defined and probably depends on the pull requests.
Reviewer:
Main powers: Retrigger only failing jobs within a CI workflow.
Assign reviewers on pull requests.
Your reviews count for the review team(s) you asked to join.
When: After leaving reviews for a few months.
Committer:
Main powers: Click the merge button once green.
Vote on project matters.
When: You can’t request this. Another Committer will have to nominate you.
I’ve usually nominated people after a year of semi-regular contributions and reviews, or sooner if the person contributes often.
If you’re planning to contribute to Cilium for a while, I’d recommend to ask to become an Organization Member as soon as possible, as it helps a lot with the CI.
Conclusion
Welcome to the community of Cilium contributors!
I hope this guide will help you make many successful contributions.
With a relatively informal process like this one, it can be hard to cover everything.
So if you notice something I didn’t cover, please reach out!
And as usual in open source, don’t hesitate to reach out to fellow contributors in public channels.
The best place for that is probably the Cilium Slack, in the #development channel I mentioned several times above.
Thanks to Simone for his help in understanding GitHub’s permission model.
Golang for the userspace parts and C for the kernel/eBPF parts. ↩
In that case, GitHub will automatically copy your commit description into the pull request description. ↩
User-visible changes correspond to labels release-note/major, release-note/minor, and release-note/bug. You should write the release note even if you don’t have permissions to set the corresponding label yourself. ↩
Of course, having more reviews can help improve the quality of the pull request. ↩
Test runs on main are always running either on push or on schedule. ↩
Under the “Summary” tab on the left, at the very bottom of the page. ↩
]]>Linux XFRM Reference Guide for IPsec2024-10-30T08:26:10+00:002025-02-13T10:31:00+00:00https://pchaigno.github.io/xfrm/2024/10/30/linux-xfrm-ipsec-reference-guideThis post focuses on the XFRM building blocks Cilium uses to provide its IPsec support.
Therefore, only tunnel mode and ESP are discussed, XFRM devices are not described, and some focus is made on the use of packet marks in XFRM policies and states.
Several others have written on XFRM, usually with a slightly different focus.
James Bottomley gave a quick introduction on his blog, with examples of configurations.
Andrej Stender’s blog has a very detailed description of the typical packet paths for IPsec gateways.
If you find mistakes, you can report them by email or via the other contact methods listed at the bottom.
IPsec encryption in the Linux kernel relies on XFRM.
XFRM is an IP framework intended for packet transformations, from encryption to compression.
It is configured via a set of policy and state objects, which for IPsec, correspond to Security Policies and Security Associations.
XFRM Policies and States
At a high-level, XFRM policies define what traffic to accept and reject, whereas states define how to perform the encryption and decryption.
Policies can match on the direction (out, in, or fwd), the source and destination IP addresses with CIDRs, and the packet mark.
As an example, the following policy matches egressing packets with any source IP address, 10.56.1.X destination IP addresses, and 0xcb93eXX packet marks.
Policies default to allowing traffic as done here.
src 0.0.0.0/0 dst 10.56.1.0/24
dir out priority 0
mark 0xcb93e00/0xffffff00
[...]
States are relatively similar, except that they are agnostic to the direction and can only match on exact IP addresses (or 0.0.0.0 to match all).
The following state will apply to packets with IP addresses 10.56.0.17 -> 10.56.1.238 and the same packet marks as above.
In the case of tunnel-mode IPsec, these IP addresses correspond to the outer IP addresses.
For ingressing, encrypted packets, the SPI will also be used (discussed below).
You may notice that nothing specifies if this state should perform encryption or decryption.
That’s because it can actually do both.
As said above, states are agnostic to the direction of traffic so the same state may theoretically be used for both encryption and decryption.
What to do will be determined based on where in the stack the state is matched (ex., decryption on ingress).
Policy Templates
XFRM policies also typically define a template, as below:
src 0.0.0.0/0 dst 10.56.1.0/24
dir out priority 0
mark 0xcb93e00/0xffffff00
tmpl src 10.56.0.17 dst 10.56.1.238
proto esp spi 0x00000003 reqid 1 mode tunnel
How this template is used depends on the direction.
For egressing traffic, the template defines the encoding to perform.
For example, the above template will encapsulate packets with an IP header and an ESP header.
The IP header will have IP addresses 10.56.0.17 and 10.56.1.238.
The ESP header will have SPI 3.
For ingressing and forwarded traffic however, the template acts as an additional filter.
The following XFRM policy for example will only allow packets if they are ESP packets with outer IP addresses 10.56.1.238 and 10.56.0.17, in addition to having a packet mark matching 0xd00/0xf00.
src 0.0.0.0/0 dst 10.56.0.0/24
dir in priority 0
mark 0xd00/0xf00
tmpl src 10.56.1.238 dst 10.56.0.17
proto esp reqid 1 mode tunnel
The template of XFRM OUT policies points to the XFRM state to use for encryption.
The IP addresses, the SPI, the protocol, the mode, and the reqid should all match between the XFRM state and the template.
XFRM Packet Flows
IPsec and XFRM are represented in the usual Linux networking diagram.
There are however several errors in that diagram when it comes to XFRM1, so I decided to write a new one.
It takes inspiration from Andrej Stender’s diagrams and simplifies the overall flow to focus on just what I want to explain here.
All pieces related to XFRM are in purple, routing decisions in orange, and the rest in yellow.
Egress Packet Flow
On egress, packets will first hit one of the XFRM OUT policy blocks.
At this point, a lookup is performed against the XFRM OUT policies.
If a match is found, the packet goes to the XFRM encode block and the template is used to lookup XFRM states.
If a state is found, its information is used to encrypt the packet.
The encrypted packet will then navigate again through the OUTPUT and POSTROUTING chains.
Ingress Packet Flow
On ingress, encrypted packets (ex., ESP packets) will hit the XFRM decode after they navigate through the INPUT chain.
In tunnel mode, encrypted packets will typically have one of the server’s IP addresses as the outer destination address, so they should automatically be routed through the INPUT chain.
If not, it may be necessary to add IP routes to redirect packets to the INPUT chain.
As an example, Cilium identifies IPsec traffic on tc-bpf ingress and marks them with a special value which is then used to reroute those packets to the INPUT chain.
At the XFRM decode, if packets match an XFRM state, they will be decoded (i.e., decapsulated and decrypted) using the state’s information.
The match is based on the source & destination addresses, the mark, the SPI, and the protocol.
In case of any decoding error (ex., wrong key), the packet is dropped and an error counter is increased.
As illustrated on the diagram, an XFRM policy matching the packet isn’t required for the decoding to happen (it goes directly to XFRM decode), but it is required for the packet to proceed to a local process or through the FORWARD chain.
An XFRM policy with an optional template (i.e., level use) will allow all decrypted packets through.
Traffic that was never encrypted, and therefore does not come from XFRM decode, is allowed by default.
After a packet is decrypted, it is recirculated in the stack, as if coming from the interface it was initially received on.
More specifically, packets are recirculated before the tc layer, such that they are visible on the tc-bpf hook a second time (once before decryption, once after).
The packet mark is preserved when recirculated, so it’s possible to identify and trace packets that have been decrypted and recirculated.
The packet mark can also be modified during decryption, using the output-mark field of the XFRM states.
Output Description of ip xfrm
The example outputs below are from iproute2-6.1.0.
More fields will likely appear in newer versions.
For example, XFRM states have a dir field in newer kernels (v6.10+), which will likely appear in the ip xfrm state output at some point.
In the ip xfrm output, policies are ordered by date of creation, with newer policies at the top.
This is important because, in case two policies match a packet and have the same priority, the newest one is used.
$ ip -s xfrm policy src 0.0.0.0/0The CIDR to match against the source IP addressdst 0.0.0.0/0The CIDR to match against the destination IP address uid 0 dir fwdStates the direction. It defines where in the Linux stack this policy will be used, between ingress, egress, and forwarding.action allowThe action to take on matching packets. Packets can only be allowed through (by default) or dropped.index 18Used to differentiate between different policies which might have the same or overlapping selectors. If not given or if it already exists, it is automatically (re-)generated (cf., `xfrm_gen_index`). The three LSBs encode the direction (ex., 1 for `XFRM_POLICY_OUT`). The MSBs are simply incremented by one (that is, the index is incremented by 8) until a free index is found.priority 2975States the priority for this policy in case multiple could match the packet. 0 is the highest priority.share anyAlways set to `any` and unused today.flag (0x00000000)Set of flags for XFRM policies. Only `XFRM_POLICY_ICMP` (0x2) is supported at the moment; `XFRM_POLICY_LOCALOK` (0x1) is not implemented (anymore?). When `XFRM_POLICY_ICMP` is given, the policy will also apply to ICMP packet with a payload packet that matches the policy's selector.
lifetime config:
limit: soft (INF)(bytes), hard (INF)(bytes)
limit: soft (INF)(packets), hard (INF)(packets)Not implement and not enforced.
expire add: soft 0(sec), hard 0(sec)
expire use: soft 0(sec), hard 0(sec)Various expiration times for the policy, based on the time since the policy was added or the time since the policy was last matched by a packet. When a soft expiration time is reached, a notification is sent to userspace via netlink (`struct xfrm_user_expire`). When a hard limit or expiration time is reached, the policy is deleted.
lifetime current: 0(bytes), 0(packets)Not implemented; will always be 0. add 2024-06-17 11:24:49 use 2024-06-17 11:25:01Timestamps for when the policy was added and when it was last matched by a packet, to be used if expiration times have been set.
tmpl src 0.0.0.0See Policy Templates for how this field is used.dst 10.92.0.164See Policy Templates for how this field is used. proto espSee Policy Templates for how this field is used.spi 0x00000000(0)See Policy Templates for how this field is used.reqid 1(0x00000001)See Policy Templates for how this field is used.mode tunnelSee Policy Templates for how this field is used. level useThe nonsensical way to indicate this template is optional, the alternative being `level required`. If no XFRM state matching the template is found, the template will be skipped if optional. Otherwise, the packet will be dropped with `XfrmInTmplMismatch`.share anyNot implemented and will always be `any`. enc-mask ffffffffBit mask defining the list of allowed encryption algorithms. See Encryption algorithms in include/uapi/linux/pfkeyv2.h for the list of possible values.auth-mask ffffffffBit mask defining the list of allowed authentication algorithms. See Authentication algorithms in include/uapi/linux/pfkeyv2.h for the list of possible values.comp-mask ffffffffNon-implemented bit mask (was probably defined for compression algorithms).
& ip -s xfrm state src 10.92.1.189The IP address to match against the packets' source IP addresses.dst 10.92.0.164The IP address to match against the packets' destination IP addresses. proto espThe IPsec protocol to use.spi 0x00000003(3)The Security Parameter Index. A tag to distinguish between multiple IPsec streams that may be using different algorithms and/or keys. Particularly useful during key rotations.reqid 1(0x00000001)An ID only used to ensure the XFRM policy template and the state match. It doesn't seem to be used for anything else in the kernel.mode tunnelStates whether the packet is encapsulated (`tunnel`) or if the ESP header is simply added to the existing packet (`transport`). replay-window 0Size of the replay window used for the anti-replay checks (i.e., toleration setting). seq 0x00000000 flag (0x00000000)Holds various flags including `XFRM_STATE_ESN` (0x80) for ESN mode. mark 0x4db50d00/0xffff0f00The value and mask used to match against the packets' marks.output-mark 0xd00/0xffffff00The value and mask to apply to the packets' marks after they have been encrypted or decrypted. aead rfc4106(gcm(aes))The type and name of algorithm in use.0x856f15d0ccabe682286b4286bccf5d595b88b168 (160 bits)The key and its size. It's of course sensitive information that should be treated as such.128The ICV length. Which lengths are supported depends on the algorithm in use.
anti-replay context: seq 0x0Holds the current receive-side sequence number, for the anti-replay check., oseq 0x0The last emitted sequence number. If this number overflows (on 32-bits), packets are dropped and the error counter `XfrmOutStateSeqError` is increased. In ESN mode, this sequence number is coded on 64-bits., bitmap 0x00000000Tracks the sequence numbers that have already been seen in the replay window. sel src 0.0.0.0/0 dst 0.0.0.0/0An additional filter applying to the decrypted packets, to ensure the inner packets are coming and going where you expect.uid 0This field appears to be unused (`user` in `struct xfrm_selector`). lifetime config:
limit: soft (INF)(bytes), hard (INF)(bytes)
limit: soft (INF)(packets), hard (INF)(packets)
expire add: soft 0(sec), hard 0(sec)
expire use: soft 0(sec), hard 0(sec)Various limits and expiration times for the state, based on the number of bytes received, the number of packets received, the time since the state was added, or the time since the state was last used for a packet. When a soft limit or expiration time is reached, a notification is sent to userspace via netlink (`struct xfrm_user_expire`). When a hard limit or expiration time is reached, the state is deleted.
lifetime current: 20124(bytes), 83(packets)Counters for bytes and packets matched by this state, to be used if limits have been set. add 2024-06-17 11:15:48 use 2024-06-17 11:16:02Timestamps for when the state was added and when it was last matched by a packet, to be used if expiration times have been set.
stats: replay-window 0Incremented whenever a packet is received with a sequence number outside the window.replay 0Incremented whenever a packet is received with a sequence number in the replay window that was already observed.failed 0Incremented when the checksums for authentication or encryption headers are incorrect (full name `integrity_failed` on kernel's side). `XfrmInStateProtoError` is always incremented when this counter is incremented.
Updating XFRM States and Policies
In Cilium, on several occasions, we had to make substantial changes to our XFRM states and policies.
In the process, we faced several conflicts: you try to add a new XFRM state and the kernel complains that it conflicts with an existing state.
These conflicts can be particularly non-obvious as they can depend on the order of additions for XFRM states.
With proper documentation that would be easy to resolve, but in its absence, you need to dig into the kernel sources to understand which fields matter to identify a state or a policy.
This section aims to document those aspects: which fields constitute the “key” of XFRM states and policies, how to avoid conflicts, and how to perform updates without dropping traffic.
Identifying Fields of XFRM States
$ ip xfrm state
src 10.36.98.139 dst 10.36.1.178
proto esp spi 0x00000003 reqid 1 mode tunnel
replay-window 0
mark 0xc90a0000/0xffff0000 output-mark 0xd00/0xffffff00
aead rfc4106(gcm(aes)) 0xf83bd6832d552fa23e9ab5fdb742e1241b054f6c 128
anti-replay context: seq 0x0, oseq 0x0, bitmap 0x00000000
sel src 0.0.0.0/0 dst 0.0.0.0/0
XFRM states are identified by their destination IP address, the masked value of the mark, the SPI, and the protocol, as shown above, in bold orange.
The source IP address and the unmasked part of the mark are not considered when identifying XFRM states.
Thus, the “key” for XFRM states could be written as:
key = (dst_ip, proto, spi, (mark_value & mark_mask))
For the mark, it checks if the sanitized value (i.e., with the mask applied) from the new mark is matched by any of the existing marks:
For example, if the new mark is 0x12345600/0xffffff00 and mark 0x12340000/0xffff0000 already exists, the new mark will be rejected.
If however 0x12345600/0xffffff00 was added first and 0x12340000/0xffff0000 is the new mark, it will be accepted.
Hence, the order of addition of XFRM states can matter.
Note that if you use unsanitized mark values, you may run into unexpected behavior at runtime.
An unsanitized value is one with bits set that are not part of the mask, ex. 0xabcd0001/0xffff0000.
If using such mark values, the kernel will apply the mask to the packet's mark and then compare it to the unsanitized value.
Therefore, it won't match any packets at runtime.
This bug concerns the marks of both policies and states, for ingress and egress.
For XFRM state deletions, note that it will complain if you pass any argument not part of the key… except for the source IP address.
But even if you give it a source IP address, it will not consider it when matching for the deletion.
Identifying Fields of XFRM Policies
$ ip xfrm policy
src 10.0.0.0/8 dst 10.36.1.0/24
dir in priority 0
mark 0x58d73e00/0xffffff00
tmpl src 10.36.1.179 dst 10.36.2.60
proto esp reqid 0 mode transport
XFRM policies are identified by their direction, source IP address & mask, destination IP address & mask, and their mark & mask, as shown above in bold orange.
However, contrary to XFRM states, the masks (ex., CIDR or mark masks) are not applied before using the related values (resp., CIDR IP addresses or mark values).
Thus, the “key” for XFRM policies could be written as:
So XFRM policies with dst 10.0.0.0/8 and dst 10.1.1.1/8 will be considered two different policies!
For updates and deletions, the exact values must be used: a more generic policy won’t be considered a match.
Seamless Updates of XFRM Policies
Updating XFRM policies without disrupting ongoing traffic is relatively easy.
If you only need to update non-identifying fields such as the priority or the template, you can simply run ip xfrm policy update.
If you however need to identify fields (ex., change the mask for marks), then you can first de-prioritize existing policies, before adding the new policies with a higher priority.
By default, policies are created with the highest priority, 0.
Thus, de-prioritizing a policy is a simple matter of running ip xfrm policy update to increase the priority value.
This guarantees that the old policies stay in place and traffic is still processed during the update.
Then, new policies can be added as usual, with a higher priority, for example 0.
Once all new policies are in place, old policies shouldn’t be used anymore and can be removed.
Seamless Updates of XFRM States
Similarly to policies, updating non-identifying fields of existing states is a simple matter of running ip xfrm state update.
If you need to update identifying fields however, there is no priority mechanism to keep both sets of states, old and new, in place during the update.
Instead, the best approach I’m aware of to avoid disrupting operations during the update is to rely on SPIs.
You can distinguish the sets of old and new states by their SPIs, for example by reserving bits in the SPI for a version number.
As an example, if your existing states have SPIs 0x0000xxxx, you could assign SPIs 0x0001xxxx for the new states.
This approach obviously requires some planning beforehand, when assigning the SPIs.
Then, you need some synchronization mechanism to only start encrypting traffic with the new SPIs once the receiver has installed XFRM states with the new SPIs as well.
Presumably, you already have such a synchronization mechanism to handle key rotations.
XFRM Errors
All XFRM errors correspond to packet drops.
Some of them may also be associated with per-state counters increasing.
CONFIG_XFRM_STATISTICS is required to see these error counters in /proc/net/xfrm_stat.
XfrmInError: If the kernel fails to allocate memory during encryption.
XfrmInBufferError:
If a packet is going through too many XFRM states.
The maximum is set to XFRM_MAX_DEPTH (6).
If too many XFRM policy templates apply to a packet.
The maximum is also set to XFRM_MAX_DEPTH (6).
XfrmInHdrError:
If the SPI portion of the packet is malformed.
If the outer IP header is malformed.
XfrmInNoStates: If no XFRM IN state was found that matches the AH or ESP packet ingressing on the INPUT chain.
XfrmInStateProtoError:
If the AH or ESP checksum is incorrect.
If the packet’s IPsec protocol (ex., AH, ESP) doesn’t match the protocol specified by the XFRM state.
Also includes all protocol specific errors (ex., from esp_input) listed below:
If decryption/encryption fails (ex., because the key specified in the XFRM IN state doesn’t match the key with which the packet was encrypted).
If the protocol headers (ex., ESP) or trailers are malformed.
If there is not enough memory to perform encryption/decryption.
XfrmInStateModeError: If the packet is in IPsec tunnel mode, but the matched XFRM state is in transport mode.
XfrmInStateSeqError: If the anti-replay check rejected the packet.
If the check failed because the sequence number was outside the window, the replay-window counter of the associated XFRM state will be incremented.
If it failed because the sequence number was seen already, the replay counter is incremented instead.
XfrmInStateExpired: There can be a delay between when a state expires (hard limits) and when it’s actually deleted.
During that time, matching packets are dropped with XfrmInStateExpired on ingress.
XfrmInStateMismatch:
If the encapsulation protocol of the XFRM state (ex., espinudp in encap field of ip xfrm state) doesn’t match the encapsulation protocol of the packet.
If the decrypted packet doesn’t match the selector (sel field) of the used XFRM state.
XfrmInStateInvalid: If received packet matched an XFRM state that is being deleted or that expired.
XfrmInTmplMismatch:
If a packet matches an XFRM policy with a non-optional template, but the template doesn’t match any of the XFRM states used to decrypt the packet (yes, a packet can be decoded multiple times).
If an XFRM state with mode tunnel was used on the packet and it doesn’t match any XFRM policy template.
XfrmInNoPols: If the ingressing packet doesn’t match any XFRM policy and the default action is set to block.
See ip xfrm policy {get,set}default to view and set the default XFRM policy actions.
XfrmInPolBlock: If the packet matches an XFRM IN policy with action block.
XfrmOutError:
If the kernel fails to allocate memory during encryption.
In some cases, if the packet to encrypt is malformed.
XfrmOutBundleCheckError: Unused.
XfrmOutNoStates: If the packet matched an XFRM OUT policy, but no XFRM state was found that matches the policy’s template.
XfrmOutStateProtoError: If a protocol-specific (ex., ESP) encryption error happens.
XfrmOutStateModeError: If the packet exceeds the MTU once encapsulated and it shouldn’t be fragmented.
XfrmOutStateSeqError: The output sequence number (oseq) of an XFRM state reached its maximum value, UINT32_MAX when not using ESN mode.
XfrmOutStateExpired: There can be a delay between when a state expires (hard limits) and when it’s actually deleted.
During that time, matching packets are dropped with XfrmOutStateExpired on egress.
XfrmOutPolBlock: If the packet matches an XFRM OUT policy with action block.
XfrmOutPolDead: Unused.
XfrmOutStateInvalid is reported instead for XFRM states that in the process of being deleted.
XfrmOutPolError:
If too many XFRM policy templates apply to a packet.
The maximum is also set to XFRM_MAX_DEPTH (6).
If no XFRM state is found for a non-optional template of the matching XFRM policy.
XfrmFwdHdrError: If the packet is malformed when going through the FWD policy check.
XfrmOutStateInvalid: If egressing packet matched an XFRM state that is being deleted or that expired.
XfrmOutStateDirError: If the direction of the XFRM state found during the lookup is defined and isn’t XFRM_SA_DIR_OUT.
Only on kernels v6.10 and newer.
XfrmInStateDirError: If the direction of the XFRM state found during the lookup is defined and isn’t XFRM_SA_DIR_IN.
Only on kernels v6.10 and newer.
Performance Considerations
This section describes the data structures used to hold the XFRM policies and states.
This is useful to understand when dealing with a large number of states and policies as the information they hold can help improve indexing and speed up the lookups.
When dealing with thousands of policies and states, the lookup cost can become non-negligible even when compared to the encryption/decryption cost.
Data Structure for XFRM Policies
XFRM policies are stored in a rather complex data structure made of multiple red-black trees and hash tables.
At the root, everything is contained in a resizable hash table indexed by network namespace, IP family, direction, and interface (in case XFRM interfaces are used).
Each entry in this resizable hash table contains several black-red trees, which themselves hold the XFRM policies.
Those entries are represented by the structure xfrm_pol_inexact_bin.
Once xfrm_pol_inexact_bin has been retrieved (based on current IP family, namespace, and direction), each of its red-black trees is looked up using the source and destination IP addresses.
The root_s tree contains policies sorted by source IP addresses; the root_d tree contains policies sorted by destination IP addresses.
In addition, leaf nodes of the root_d tree also contain another tree with policies sorted by source IP addresses.
That allows the lookups into root_s and root_d to return three lists of candidate (src_ip; dst_ip) policies from the leaf nodes:
A list of (src_ip; any) candidates from root_s.
A list of (any; dst_ip) candidates from root_d.
A list of (src_ip; dst_ip) candidates from the trees pointed by the leaf nodes of root_d.
These three lists of candidate XFRM policies are completed by a list of (any; any) candidates directly stored in the xfrm_pol_inexact_bin entry.
Note that an XFRM policy will only be present in one of the four candidate lists, according to its source and destination CIDRs.
These four lists of candidate XFRM policies are then evaluated.
The kernel iterates through each list, looking for the highest-priority (lowest priority number) candidate that matches the packet.
If two policies match and have the same priority, the newest one is preferred.
It’s also only during this linear evaluation of candidates that the packet mark is compared with the policy marks.
Data Structure for XFRM States
XFRM states are organized in four hash tables, with different XFRM fields used for indexing and different purposes:
net->xfrm.state_bydst is indexed by source and destination IP addresses as well as reqid.
net->xfrm.state_bysrc is indexed only by source and destination IP addresses.
net->xfrm.state_byspi is indexed by destination IP address, SPI, and protocol.
net->xfrm.state_byseq is indexed by sequence number only.
net->xfrm.state_byspi is used when looking up an XFRM state for ingressing packets.
This makes sense to speed up the search as each XFRM state is encouraged to have its own SPI (cf., RFC4301, section 4.1) and the encrypted packets carry the SPI.
When searching for the XFRM state that corresponds to an XFRM policy template (before encryption), net->xfrm.state_bydst is used.
That makes sense because the indexing information is what the XFRM policy template provides.
That hash table is typically also the one being used when iterating through all XFRM states (ex., when flushing them), but any hash table would do the job for that.
net->xfrm.state_bysrc and net->xfrm.state_byseq are used for various other management tasks, such as looking up an XFRM state to update, answering a netlink query from the user, or checking for existing states before adding a new one.
Conclusion
There’s still a lot that would need to be covered for this guide to be a complete reference on XFRM/IPsec in Linux.
To cite a few, this guide didn’t cover XFRM interfaces, VTIs, ESP-in-TCP, ESP-in-UDP, XFRM offloads, or per-resource child SAs.
Nonetheless, it should constitute a good basis to configure and troubleshoot XFRM configurations for IPsec tunneling.
Thanks to Louis, Gray, and Simone for identifying several mistakes and helping with wordsmithing.
For example, after XFRM decode, packets actually hit the tc/qdisc of the ingress device again, as you can see if you hook into tc-bpf. ↩
]]>Research Grant from the eBPF Foundation2024-04-02T08:26:10+00:002024-04-02T08:26:10+00:00https://pchaigno.github.io/ebpf/2024/04/02/research-grant-ebpf-foundationLast year, the first workshop entirely dedicated to eBPF was hosted by the SIGCOMM conference.
Today, I’m happy to share the first eBPF research grant, from the eBPF Foundation!
Despite being developed and maintained in large part by industry, eBPF has always had strong ties with the academic community.
The eBPF ancestor, cBPF, was first published at Usenix Winter 1993.
Subsequent work on eBPF, such as XDP or PREVAIL, was also published at top academic conferences, often in the context of industry-academia partnerships.
In addition, on multiple occasions, Alexei Starovoitov stated his goal to build eBPF as an enabler for innovation.
I believe this was always well understood by the academic community, with papers at top conferences regularly building on eBPF1.
This new grant comes as a $25–50k unrestricted gift and can for instance be used to cover part of a PhD student’s salary.
I hope it will serve as an additional incentive for the kernel and academic communities to collaborate.
I’m a strong believer that the kernel community would benefit from further research on eBPF and its verifier, particularly in formal verification, static analysis, and compiler theory.
Thanks a lot to Daniel Borkmann and Bill Mulligan for setting this up!
The Hyperupcalls (ATC’18), hXDP (OSDI’20), BMC (NSDI’21), and Tigger (VLDB’23) papers come to mind, among many others. ↩
]]>PREVAIL: Understanding the Windows eBPF Verifier2023-09-06T08:26:10+00:002023-10-30T14:50:00+00:00https://pchaigno.github.io/ebpf/2023/09/06/prevail-understanding-the-windows-ebpf-verifierIn 2021, Microsoft open sourced their eBPF-for-Windows project.
They rely on existing open-source projects to JIT-compile, interpret, and verify BPF programs.
Interestingly, PREVAIL, the BPF verifier they use, originated from peer-reviewed academic work and contrasts significantly with the Linux verifier.
In this blog post, I’ll summarize the PREVAIL paper with a strong focus on its design.
I will also introduce its formalism and have a quick look at the evaluations.
The PREVAIL implementation evolved a lot since the paper was published in 2019, yet the design stayed the same.
Some of the limitations may have been removed and the evaluation numbers may have changed.
In this paper, the authors introduce PREVAIL1, an alternative static analyzer for eBPF bytecode, using abstract interpretation techniques.
As is the usage, they introduce their results in the abstract:
Our evaluation, based on real-world eBPF programs, shows that [PREVAIL] generates no more false alarms than the existing Linux verifier, while it supports a wider class of programs (including programs with loops) and has better asymptotic complexity.
Early in the paper, the authors make one important observation:
The need for a better verifier is widely recognized by eBPF developers.
That’s true and I’m glad to see it is also clear to the academic community.
They describe four aspects on which the verifier could be improved:
First, the verifier reports many false positives, forcing developers to heavily massage their code for the verifier to accept it, e.g., by inserting redundant checks and redundant accesses.
Second, the verifier does not scale to programs with a large number of paths.
Third, it does not currently support programs with loops.
Finally, the verifier lacks a formal foundation.
The first and second points are probably the main issues today.
Because the verifier runs on low-level bytecode, it doesn’t have all of the high-level information from the original C program2.
As a result, it sometimes struggles to keep track of and verify code optimized by the compiler3.
The second point only affects large BPF projects such as Cilium, but can be hard to resolve, as small changes in the code and compiler options can lead the verifier to reject programs.
On newer kernels, support for function-by-function verification makes this a lot more manageable, by allowing developers to break programs into smaller pieces.
Support for bounded loops was merged in Linux v5.3.
It was then extended to support various loop structures of arbitrary sizes via BPF helpers (bpf_loop) and kfuncs (e.g., bpf_iter_num_next and bpf_for macro).
Finally, I’m not sure the lack of formal foundations should be an argument in itself, but I guess the point is that formal foundations would allow us to reason about the correctness of the verifier.
Abstract Interpretation
This section aims to provide a short introduction to abstract interpretation, the static analysis technique used by PREVAIL.
I’ll focus on the minimal information needed to understand the paper.
For a more thorough introduction, you can refer to the Mozilla wiki.
Introductory Example
Abstract interpretation is a technique for static program analysis, used to analyze a program’s behavior over all possible inputs.
Since finding all possible runtime errors in an arbitrary program is undecidable, static analysis trades complete coverage of possible inputs for an approximate result (e.g., rejecting safe programs).
Abstract interpretation achieves this by using abstract values for variables.
As an example, we will analyze the snippet of BPF bytecode below with integer intervals as abstract values for our variables.
This snippet of bytecode reads 16 bits from memory (instruction 4), at offset r0 + r1, with r0 pointing to a BPF map value.
At instruction 1, we check that the value in r1 is bounded. If it is not, we bound it with a bitmask at instruction 2.
// r0 is a non-null pointer to a map value.
// r1 initially can be any positive value on 64-bits.
0:r6=r01:ifr1<14gotopc+1// Jump to insn 3 if r1 is bounded.
2:r1&=0xf// If it is not, bound it.
3:r6+=r14:r7=*(u16*)(r6+0)// Read map value.
We are interested in the value of r1 at the entry of instruction 3, before it’s used for a memory access.
The initial abstract value for r1 is [0; MAX_UINT64].
It represents the set of possible concrete values r1 can take at instruction 0.
When we reach the conditional jump, we analyze both paths.
If the condition is true, then we can update the abstract value to [0; 13].
If false, we reach instruction 2 and can update r1 to [0; 15].
So far it looks very similar to what the Linux verifier would do.
That changes at instruction 3.
Instead of continuing to analyze the two paths independently, we will use the join operation4, ⨆.
In particular, we can define the abstract value of r1 at instruction 3 as the join of r1’s abstract values after instructions 1 and 2, that is [0; 13] ⨆ [0; 15] = [0; 15].
This analysis tells us that the memory access at instruction 4 is unsafe (out of bounds) if the map value is 16-bytes long or less (2 bytes access at maximum offset 15).
See the addendum for a second example in which the integer intervals leads to a loss of precision and a false positive.
Abstract Domains
The Interval abstract domain, which we’ve used above, is only one domain among many that can be used for abstract interpretation.
We can cite for example, the Parity domain, to track odd and even numbers, or the Polyhedra domain, which can track linear relationships between variables.
The table below5 gives a few examples of abstract numerical domains, from least expressive to most expressive (c and a being constants, x variables).
The abstract domain to use depends on the application and is often a tradeoff between the computational cost and what can be analyzed.
Numerical domain
Representable constraints
Parity
x % 2 == c
Interval
±xi <= c
Zone
(±xi <= c) and (xi - xj <= c)
Octagon
(±xi <= c) and (±xi ± xj <= c)
Polyhedra
a1x1 + a2x2 + ... +anxn <= c, ai ∈ Z
So for example, with the Interval domain, you could imagine having constraints x1 <= 2, -x1 <= 0, and x2 <= 0.
In other words, x1 ∈ [0; 2] and x2 ∈ ]-∞; 0].
More expressive abstract domains are also usually more expensive.
For example, while the join operation for the Interval domain has complexity O(n) (with n the number of variables), the same operation has complexity O(n²) in the Octagon domain.
One important aspect of the domain’s expressiveness is whether they are relational, meaning that they can express relations between variables.
Zone for example can preserve some relations between variables xi and xj with its second constraint type.
In the table above, we can see that Zone, Octagon, and Polyhedra are relational domains, while Parity and Interval are non-relational.
For more information on abstract domains, you can check these PLDI 2015 slides, which include a walkthrough of a program analysis with Octagon (slides 14–30).
The POPL 2017 presentation from the same author includes an example assertion that can be proven by Polyhedra but not by Octagon.
Let’s go back to our PREVAIL paper.
Abstract Domain Requirements for PREVAIL
Using a couple of example BPF programs, the authors make several observations that will drive the design of PREVAIL.
An eBPF program can access a fixed set of memory regions, known at compile time. […] The program can acquire access to additional regions via the maps API [5]. Such regions can be shared by multiple processes, as well as between kernel and user-space applications.
This is a key observation for memory accesses.
BPF programs can access different memory regions including the stack, context (e.g., skb_buff), packet data, and map values.
All of these regions except the packet have a static size, known at the time of verification.
Because the size of the packet is not known during verification, developers of BPF programs must implement bounds checks on the packet.
For example:
This leads the authors to make the following observation:
Observation 1. The analysis must track binary relations among registers.
In other words, to understand the bounds of packet_ptr, the analysis must be able to track relations between variables (in our case, between data_end and packet_ptr + access_size).
That in turns limits the choice of abstract domain to relational abstract domains.
Observation 2. The analysis must track values in memory, including relations between different locations, as if they were registers.
This second observation comes from the use of register spilling.
When all registers are in use, the compiler can move some of their contents to the stack, to load it back into registers at a later time.
If we don’t track those register contents while on the stack, we would lose all of their information.
Observation 3. As eBPF programs are getting larger and more complex, verification via path enumeration is becoming infeasible.
The number of paths through a program grows exponentially with the number of branches.
To scale to large programs, the Linux verifier makes use of state pruning, which allows it to recognize already-verified states.
Abstract interpretation is an interesting alternative as it was designed specifically to address this problem.
Formalism of PREVAIL
I’ll now dive into the formalism of PREVAIL.
I will give pointers to understand the notations and some of their underlying intuitions.
If that aspect doesn’t interest you, you can skip ahead to the implementation.
Formal Representation
eBPF programs manipulate two kinds of regions: private regions, which can be accessed only by the program, and shared regions, which are used for intra-kernel inter-process communication.
The authors distinguish between private (stack, context, packet) and shared (e.g., map values) memory regions.
Map values are shared memory regions because they may be modified at any time by another process or BPF program.
As such, they need special handling in the verifier.
We distinguish numerical values from pointers using tags: a value tagged num is a numerical value, while a value tagged R is a pointer offset into region R.
PREVAIL models every variable with a tag and value.
Scalars are tagged num, stack pointers stk, packet pointers pkt, etc.
For pointers, the value represents the offset into the memory region represented by the tag.
Therefore, (pkt, 4) is a pointer at offset 4 into the packet, whereas (num, 4) represents the integer 4.
To represent the tags of shared memory regions (e.g., maps), the authors use the sizes of these regions:
First we abstract the tags of pointers to shared regions by the sizes of the regions they point to. This bounds the number of possible tags in any program P.
The downside of this simple approach is that PREVAIL can’t tell two pointers to shared regions of the same size apart.
The authors therefore need to forbid subtractions and comparisons between such pointers.
as we can no longer tell whether two pointers to a shared region of size K point to the same region or not, we strengthen Safe() to forbid subtraction and less-than comparison between such pointers.
Because of that change, PREVAIL can reject BPF program the Linux verifier would accept, but I doubt many programs are in this case in practice.
The grammar in the above figure formalizes the primitive eBPF operations that PREVAIL supports.
The first operation defines assignments and ALU operations, while the second and third define load and store instructions respectively.
assume is used to state the conditions of conditional jumps.
shared K returns a pointer to a shared memory region of size K, typically for a BPF map lookup.
Formalizing Memory Writes
In the following, I will focus on the formalism for the store operation, used to write to memory.
See the paper for other operations.
PREVAIL deems a store of sz bytes at memory pointed by p safe if:
it is within the bounds of the memory region of p, noted eρ(p), and
p is a pointer (i.e., not tagged num), and
in case the stored value x is a pointer, p points to the stack.
The third condition is meant to ensure that pointers are never written to externally-visible memory locations (e.g., the packet) as that would lead to pointer leaks.
You can also notice that in case p is a packet pointer, the upper-bound check is performed against the special variable data_end instead of the static region size, sizeof(R).
The authors then define how the different eBPF operations impact the verification state.
The verification state is defined by the triple σ = (e, μ, ζ), with e being the set of registers, μ the set of memory cells on the stack, and ζ the set of stack addresses holding scalars.
The example for an assignment of immediate value K to register w is trivial; it simply associates register w to state (num, K) in e:
As shown below, the store operation is a bit more involved to track.
First, if the store is to a region other than the stack, the verification state can be left as is; it doesn’t need to be tracked.Otherwise, both μ and ζ need to be updated.In μ, the register e(x)=(R,n) is associated to the memory cell defined by its position en(p) and size sz.Any other memory cell overlapping with this store is removed from μ.Finally, addresses overwritten by the store are added or removed from ζ depending on whether the stored register x holds a scalar or not.
Implementation of PREVAIL and Limitations
The implementation section helps to understand the main limitations of PREVAIL.
Most of those limitations are simply gaps in the initial implementation and are not caused by the use of abstract interpretation.
[PREVAIL] maintains a variable for every one of (the finite number of) possible cells in the memory, and instantiates the underlying domains to track the values as if every cell is a (syntactic) analysis variable
Each stack slot (memory cells μ, if you’ve read the formalism section) is tracked as a separate variable.
As we’ve seen in the introduction to abstract domains, the complexity of abstract domain operations usually grows with the number of variables.
So PREVAIL is likely to consume significantly more resources for BPF programs using a lot of stack slots.
PREVAIL translates eBPF binaries into a CFG-based language understood by Crab [30]—a parametric framework for modular construction of abstract interpreters.
Note this intermediate Crab language was later removed (cf. vbpf/ebpf-verifier#87).
That led to a significant reduction of the memory consumption.
We encode abstract tags as constant numbers and used the same abstract domain to track values and tags together. […] We handle null checks by tracking absolute values of pointers in addition to offsets
I was a bit surprised by these changes.
I would have thought tags could be encoded with a much simpler abstract domain than values.
But I also thought the null checks could have been handled with additional tags as in the Linux verifier6 to avoid having to track absolute values of pointers.
Bitwise operations are not tracked precisely. Instead we use efficient over-approximations, e.g., we approximate w &= x (bitwise and) when x > 0 with assume(w<x).
PREVAIL over-approximates bitwise operations, potentially leading to false positives.
The Linux kernel does the same, but with what looks like a much more precise over-approximation, using tristate numbers (tnums).
The initial PREVAIL implementation also doesn’t support a lot of the more advanced eBPF features, such as BPF function calls, packet resizing, map-in-maps, and most helpers.
This lack of support would clearly prevent the use of PREVAIL for the largest BPF users out there (e.g., Cilium and Katran), but there do not seem to be any real blockers to their implementation.
Support for 32-bit arithmetic was also missing, which means programs compiled with mcpu=v3 would likely be rejected7.
That was covered last year (cf. vbpf/ebpf-verifier#419).
Our verifier does not currently implement termination check.
Finally, at the time the paper was written, PREVAIL didn’t ensure programs terminate.
That was fixed in 2021 (cf. vbpf/ebpf-verifier#139) with a new abstract value max_instructions.
The constraint max_instructions < 100000 is added such that the longest path through the program can have at most 100k instructions8.
Accuracy and Cost Evaluations
The authors evaluate the accuracy (number of false positives) and runtime cost (duration and memory consumption of the analysis) of PREVAIL.
To that end, they rely on a corpus of 192 BPF programs from six open source projects including Linux, Open vSwitch, Suricata, and Cilium.
BPF programs in the corpus are either of a small size (e.g., Linux samples) or networking-related; it doesn’t include any large tracing program for example.
The Cilium samples are also quite old and appear to have been generated with options that don’t maximize the programs’ size and complexity.
Nevertheless, the corpus includes a good variety of programs, with some in the thousands of instructions.
The authors first measure the accuracy of PREVAIL when using different abstract domains.
The Interval domain is clearly not adapted to verify BPF programs and serves more as a reference.
This evaluation is useful to guide a choice between the other, more expressive domains.
Since, as we will see, the accuracy also depends on the implementation of those domains, the choice is not apriori obvious.
the numerical abstract domains used in our final evaluation are:
oct-elina: Octagon using online decomposition [48].
poly-elina: Polyhedra using online decomposition [49].
I mentioned all of these domains before and, here again, they are ordered from least expressive to most expressive.
Elina and Crab refer to the libraries used to implement those abstract domains.
Online decomposition is an optimization that partitions the set of program variables into disjoint subsets maintained throughout the analysis.
Since the cost of most abstract domain operations grows exponentially with the number of variables, this optimization helps limit that growth.
Abstract domain
Number of programs for which verification failed
interval
64/192
zone-crab
2/192
zone-elina
2/192
oct-elina
2/192
poly-elina
23/192
The above table shows the number of programs that each abstract domain was unable to verify among the corpus.
As expected, Interval was only able to verify two thirds of all programs, probably because it can’t track relations between variables.
Conversely, the result for poly-elina is surprisingly bad given Polyhedra is the most expressive domain in the set.
The authors however explains that this is due only to a limitation of the Elina implementation of that domain:
The implementation uses 64-bit integers for representing the coefficients, and falls back to top when the coefficients cannot be represented precisely using 64 bit.
Of course, more expressive abstract domains come at a price.
The following two figures represent the verification time in seconds (left) and the memory consumption in GB (right) for each abstract domain.
The Interval domain has the lowest costs.
All other domains have much larger costs, except maybe for zone-crab which still requires around 5s and 1.5GB of memory to verify the largest programs.
Given that 1.5GB of memory is still too much for the Linux kernel, the authors suggest running PREVAIL in userspace9.
As a point of comparison, the Linux kernel takes about a second and consumes only MBs of memory in the worst case.
That makes it faster than even the Interval domain.
Of course, as the authors note, the current corpus is biased toward the Linux verifier since all its programs were successfully loaded on Linux.
The actual runtime of zone-crab is roughly linear in the number of instructions, despite its cubic worst-case asymptotic complexity.
As the authors note, if zone-crab behaves well in practice, it’s worst-case runtime is actually cubic.
It would be interesting to see if it’s possible to craft a BPF program that exhausts the verifier’s resources in this way.
The Linux verifier faces the same threat and currently mitigates it by enforcing various complexity limits on the input programs (e.g., BPF_COMPLEXITY_LIMIT_STATES).
It’s a bit disappointing that the paper doesn’t include any comparison with the Linux verifier on the same corpus of BPF programs.
The authors also mention PREVAIL was able to verify nine programs rejected by the Linux verifier, but without providing more details.
Conclusion
I’m always super excited to read about alternatives to the Linux BPF verifier, and this paper is no exception!
If like me you don’t have a background in formal methods, the paper can be a bit hard to understand.
Hopefully, I gave enough pointers in this blog post to help with that.
Definitely worth a read!
This academic project is also one of the lucky few that already had a “real-life” application two years after their publication.
The implementation evolved a lot during those two years and continues to.
It would therefore be interesting to see how the performance compares to two years ago—and maybe how it now compares to the Linux verifier.
Thanks to Aditi for her review and suggestions on an earlier version of this post!
Addendum: False Positive Example
Using integer intervals to track the possible values of variables can be imprecise, even if your variables are indeed integers.
Consider the example bytecode below.
We bound check r1 and r2, then multiply them together, and use the result to decide whether to execute a division by zero.
We want to check with abstract interpretation if the division by zero will ever be executed.
After instruction 2, both r1 and r2 have abstract value [0; 10].
After instruction 3, r1 holds the multiplication of r1 and r2 and therefore has abstract value [0; 100].
When considering the condition at instruction 4, because 11 ∈ [0; 100], we will walk both paths and hit the division by zero.
Except we know that r1 can never take value 11.
There are no two numbers between 0 and 10, that once multiplied together, can give 11 (said otherwise, 11 is a prime number).
When using integer intervals as abstract values, we will lose that information during the multiplication.
That loss of precision can lead to false positives, such as rejecting a program because of a never-executed division by zero in our example.
↩
Footnotes
PREVAIL stands for “Polynomial-Runtime eBPF Verifier using an Abstract Interpretation Layer”. ↩
That is quickly changing with BTF, which can preserve type information from the C program. ↩
For example, Clang 11.0.0 sometimes moves NULL checks after pointer arithmetic on map values, which causes the verifier to error with “pointer arithmetic on map_value_or_null prohibited, null-check it first”. ↩
Abstract interpretation defines other operations on abstract values, such as widening and narrowing, which can be used to analyze loops without walking each iteration. ↩
That is how the eBPF-for-Windows project ended up using PREVAIL. ↩
]]>eBPF Instruction Set Extensions2021-10-20T16:00:10+00:002025-01-23T14:31:00+00:00https://pchaigno.github.io/bpf/2021/10/20/ebpf-instruction-setsNot everyone who develops BPF programs knows that several versions of the instruction set exist.
This isn’t really surprising given documentation on the subject is scarce.
So let’s go through the different eBPF instruction sets, why they exist, and why their choice matters.
LLVM’s Backend Selector
If you’ve been using llc to compile your BPF program, you might have noticed an -mcpu parameter.
The help output gives us the following information:
$ llc -march=bpf -mcpu=help
Available CPUs for this target:
generic - Select the generic processor.
probe - Select the probe processor.
v1 - Select the v1 processor.
v2 - Select the v2 processor.
v3 - Select the v3 processor.
v4 - Select the v4 processor.
Available features for this target:
alu32 - Enable ALU32 instructions.
dummy - unused feature.
dwarfris - Disable MCAsmInfo DwarfUsesRelocationsAcrossSections.
Use +feature to enable a feature, or -feature to disable it.
For example, llc -mcpu=mycpu -mattr=+feature1,-feature2
That parameter allows us to tell LLVM which eBPF instruction set to use.
It defaults to generic, an alias for v1, the oldest instruction set.
probe will select the newest instruction set your kernel supports.
We will see below that selecting newer versions allows LLVM to generate smaller and more efficient bytecode.
Descriptions
The first two extensions of the base instruction set, v2 and v3, add support for new jump instructions.
The fourth extension adds a whole set of new instructions, for the most part related to signed operations.
Each new extension includes all instructions from previous extensions.
Version Two
v2 adds support for lower-than jumps where only greater-than jumps were previously available.
Of course, the first kind of jumps can be rewritten into the second, but that requires an additional register load:
// Using mcpu=v1:
0:r2=71:ifr2s>r1gotopc+1// Using mcpu=v2's BPF_JSLT:
0:ifr1s<7gotopc+1
Version Three
The second extension, v3, adds 32-bit variants of the existing conditional 64-bit jumps.
Again, you can work around the lack of 32-bit conditional jumps by clearing the 32 most-significant bits.
But using 32-bit conditional jump is shorter:
0:call bpf_skb_load_bytes
// Using mcpu=v2's 64-bit jumps:
1:r0<<=322:r0s>>=323:ifr0s<0goto+1785<LBB10_90>// Using mcpu=v3's 32-bit jumps:
1:ifw0s<0goto+1689<LBB10_90>
w0 is the 32-bit subregister of r0.
Version Four
The latest extension, v4, adds seven new instructions.
Most are related to signed operation, though there is also a new unconditional jump instruction and a new byte-swapping instruction.
Their format is described in details in the original proposal by Yonghong Song.
(Syntax highlighting is a bit off on the examples here because I haven’t yet updated the BPF lexer.)
The fourth extensions adds support for signed division and modulo operations.
Those were simply not supported before.
Trying to compile a signed division with mcpu=v3 will error with Unsupport [sic] signed division for DAG.
// C code: s64 y = x / -5;
// Using mcpu=v4's signed division:
1:r1s/=-0x5
This fourth extension also added support for sign-extended load, store and mov operations.
Those were already possible, but required two more instructions to extend the sign to the expected size.
// C code: s64 y = e->pid;
// Using mcpu=v3:
1:r1=*(u32*)(r6+0)2:r1<<=0x203:r1s>>=0x20// Using mcpu=v4:
1:r1= *(s32*)(r6 +0)
Not everything in the fourth extension is about signed operations!
It also added a new unconditional jump with a 32-bit jump offset.
The existing unconditional jump only supported 16-bit offsets.
When programs have a lot of instructions (e.g., unrolled loop), it’s easy to end up needing a longer jump.
In such cases, the compiler would simply error out with LLVM ERROR: Branch target out of insn range.
// Largest-possible unconditional jump with mcpu=v3:
1:goto+0x7fff <LBB0_2>
// Largest-possible unconditional jump with mcpu=v4:
1:gotol +0x7fffffff<LBB0_2>
Finally, mcpu=v4 added support for unconditional byte-swapping instructions.
Until now, the be{16,32,64} and le{16,32,64} instructions would only swap bytes on their respective architecture: le16 will only swap the two bytes on big endian CPUs and vice versa.
// C code: u64 y = __builtin_bswap32(x)
// Using mcpu=v3 on little endian:
1:r1=be32r1// Using mcpu=v3 on big endian:
1:r1= le32r1// Using mcpu=v4 on any CPU:
1:r1= bswap32r1
Prerequisites
You need recent-enough versions of Linux and LLVM to use the instruction set extensions.
The following table sums it up.
The BPF FAQ also gives good insight into why these instruction set extensions exist:
Why BPF_JLT and BPF_JLE instructions were not introduced in the beginning?
A: Because classic BPF didn’t have them and BPF authors felt that compiler workaround would be acceptable.
Turned out that programs lose performance due to lack of these compare instructions and they were added.
These two instructions are a perfect example of the kind of new BPF instructions that are acceptable and can be added in the future.
These two already had equivalent instructions in native CPUs. New instructions that don’t have one-to-one mapping to HW instructions will not be accepted.
Impact on Program Size and Complexity
Why does all this matter?
Is it so bad to use the default v1 instruction set?
Can we just set mcpu=probe?
Let’s first have a look at the impact on the program sizes.
To that end, we can use Cilium’s BPF programs.
They are open source, of heterogeneous sizes, and used in production systems.
In the latest stable Cilium version, v1.16.5, the largest BPF programs are in bpf_host.c.
Cilium’s TestVerifier go test loads the programs in the kernel and retrieves various statistics.
In the following, I’m using it with LLVM 18.1.8.
$ git checkout v1.16.5
$ for v in v1 v2 v3 v4;do\sed-i"s/mcpu=v[1-4].*/mcpu=$v/" bpf/Makefile.bpf &&\
make -C bpf KERNEL=netnext &&\f=${v/ /-}-bpf_host.txt;\
go test-execsudo-v-run TestVerifier/bpf_host/1 ./test/verifier/ \-cilium-base-path$(pwd)-ci-kernel-version netnext >$f;\done
As expected, each newer instruction set version generates smaller BPF programs.
Since the new instructions have a one-to-one mapping to x86 instructions, we can expect a similar impact on the size of the JIT-compiled programs.
You can therefore expect a small performance benefit in most cases when using newer instruction sets.
For larger programs and kernels before v5.23, the v2 and v3 instruction sets may also allow you to reduce your program size below the 4096 instruction limit imposed by the verifier.
It is however not the only limit imposed by the verifier.
A more common source of problems for large programs is the limit on the number of instructions analyzed by the verifier.
As the verifier analyzes all paths through a program, it counts how many instructions it has already analyzed and stops after a given limit (e.g., 1 million on Linux 5.2+).
We’ll refer to the number of instructions analyzed by the verifier as the complexity of the BPF program.
In the worst case, the complexity grows exponentially with the number of conditions in the program4.
TestVerifier also reports the complexity of each loaded BPF program.
I executed it on a Linux 6.8 and report the results in the following plot.
By clicking on the legend to hide v3 and v4, we can notice that v1 and v2 are fairly close.
There are however stricking differences between the first two versions and the third one.
The v3 instruction set sometimes reduces complexity and other times exacerbates it.
The v4 instruction set has a similar impact to v3, though not to the same extent.
It’s unclear why the newer instruction sets sometimes increase complexity when they reduce the number of instructions.
Given that they don’t significantly modify the control flow, it could be that they reduce the efficiency of the verifier’s state pruning.
To sum up, if you are having complexity issues (i.e., hitting the verifier’s threshold), you need to carefully test the impact of each instruction set before making the switch.
Conclusion
We have seen that the Linux kernel supports not one but three eBPF instruction sets!
These instruction sets have an impact on program size and performance, and in most cases, you’re better off setting mcpu=probe to use the newest supported version.
If you have very large BPF programs, a version switch can lead to a reject by the kernel’s verifier, if you hit the complexity limit, so you should test thoroughly before making the switch.
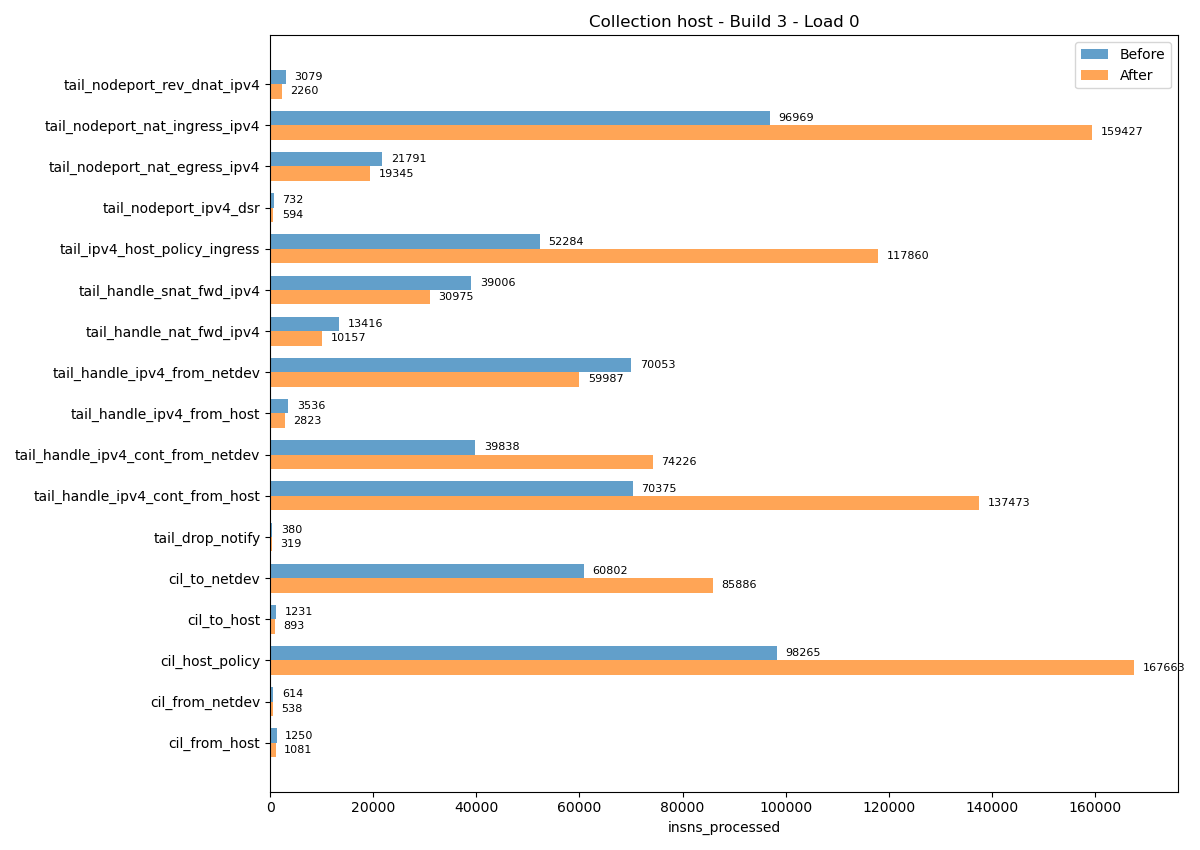






















, shown for several abstract domains.")
, shown for several abstract domains.")
{kind=link}